3D модели вирусов человека. Часть вторая: молекулярное моделирование и биоинформатика
Друзья, с момента основания проекта прошло уже 20 лет и мы рады сообщать вам, что сайт, наконец, переехали на новую платформу.
Какое-то время продолжим трудится на общее благо по адресу
На новой платформе мы уделили особое внимание удобству поиска материалов.
Особенно рекомендуем познакомиться с работой рубрикатора.
Спасибо, ждём вас на N-N-N.ru
Источник: habrahabr.ru
В нашем первом посте про трехмерное моделирование вирусов мы перечислили основные стадии процесса и рассказали о том, с чего мы начинаем и как собираем исходную информацию. В этой заметке мы расскажем о следующем этапе работы — о создании моделей отдельных молекул, из которых впоследствии будет собрана целая частица.
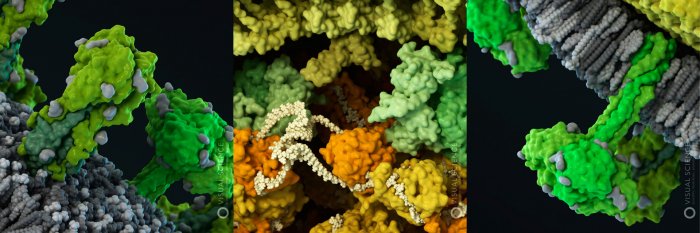 Компоненты вирусной частицы Гриппа A/H1N1
Компоненты вирусной частицы Гриппа A/H1N1
Вирусная частица — это молекулярный механизм, решающий две принципиальные задачи. Во-первых, частица должна обеспечить упаковку вирусного генома и его защиту от деструктивных факторов среды, пока вирус путешествует из клетки, в которой он собрался, к клетке, которую он сможет заразить. Во-вторых, частица должна быть способна присоединиться к заражаемой клетке, после чего доставить вирусный геном и сопутствующие молекулы внутрь, чтобы запустить новый цикл размножения. Задач не очень много, поэтому вирусы, за редким исключением, могут позволить себе быть довольно экономными в том, что касается структуры.
В частности, геном большинства вирусов невелик и кодирует не очень много белков, нередко это число меньше 10. При этом вирус может заставить клетку синтезировать большое количество однотипных белков, из которых потом соберется вирусная оболочка — капсид. Таким образом, вирусные частицы обычно состоят из большого числа одинаковых элементов, которые связываются друг с другом как детали конструктора, часто образуя регулярные и симметричные структуры. Так, очень многие, хоть и не все вирусные упаковки или их фрагменты имеют спиральную или икосаэдрическую форму.
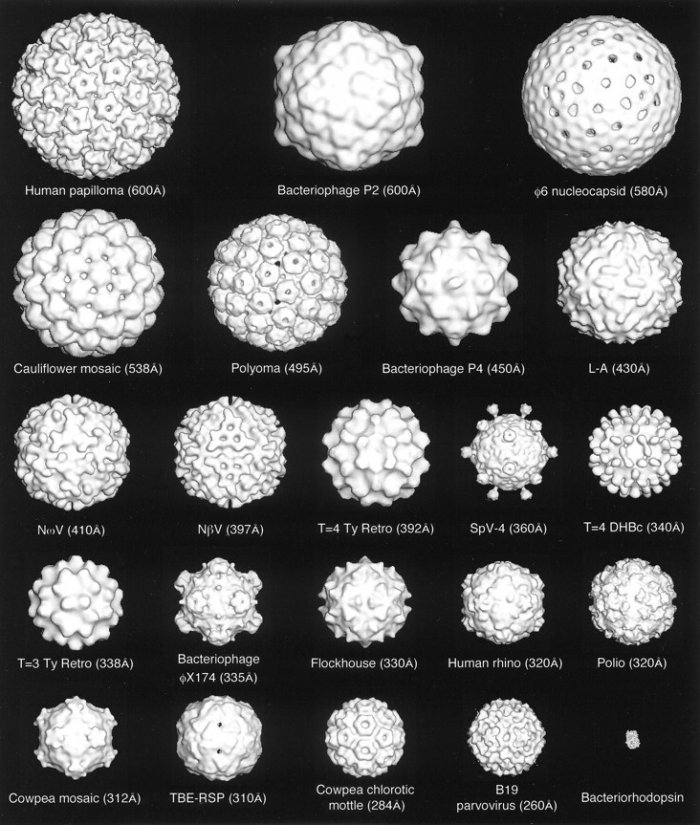 Примеры вирусных капсидов с икосаэдрической симметрией. Молекула бактриородопсина в правом нижнем углу — для сравнения. (Иллюстрация из обзора).
Примеры вирусных капсидов с икосаэдрической симметрией. Молекула бактриородопсина в правом нижнем углу — для сравнения. (Иллюстрация из обзора).
Для сборки модели вируса принципиально важно знать, как устроены отдельные белки общей структуры и как они друг с другом связываются, эту структуру формируя. Современная наука владеет целым набором методов, которые могут дать ответы на эти вопросы, однако ни один из подходов, к сожалению, не является универсальным и решает только часть задач которые стоят перед нами при создании научно достоверных моделей вирусов с атомной детализацией.
Белки: как получают, хранят и отображают информацию об их структуре?
Напомним, что белки — это полимерные молекулы, состоящие из последоватльно связанных между собой мономеров — аминокислот. В водных растворах белки обычно сворачиваются в сложные трехмерные глобулы (почти как головоломка “Змейка Рубика”), форма которых зависит от аминокислотного состава и некоторых других факторов. Пространственное строение этих глобул определяют в основном методами рентгеноструктурного анализа и ЯМР-спектроскопии. Также в последнее время к этой задаче позволяет подойти электронная микроскопия.
В целом, методы определения пространственной структуры молекул сложны и имеют целый набор ограничений, поэтому далеко не все вирусные белки описаны полностью. Так, рентгеноструктурный анализ предполагает наличие кристалла, через который пропускается рентгеновское излучение. Атомы кристалла провоцируют дифракцию рентгеновских лучей, по картине которой можно оценить распределение электронных плотностей в кристалле, а по этим данным уже восстановить расположения конкретных атомов. Этот метод дает разрешение вплоть до чуть более 1 ангстрема (0,1 нм), однако в случае белков проблема заключается в том, что далеко не все из них можно кристаллизовать. Особенно сложным это оказывается, если белок имеет гибкие подвижные или заякоренные в мембране фрагменты.
ЯМР-спектроскопия основана на явлении ядерного магнитного резонанса и позволяет описывать строение белков в растворе. Этот подход выявляет набор возможных положений атомов в молекуле и, в отличие от предыдущего метода, дает возможность оценить степень гибкости тех или иных ее участков. Но ЯМР-спектроскопия хорошо работает только для сравнительно небольших молекул, поскольку крупные белки дают слишком много шума.
Электронная микроскопия позволяет описать строение крупных молекулярных комплексов, что бывает очень полезно, когда речь идет о вирусах. Для многих симметричных структур можно получить большой набор изображений под разными углами, проанализировав которые можно воссоздать трехмерную картину. Для отдельных объектов разрешение, получаемое в результате применения разных вариантов электронной микроскопии (до 4–5 ангстрем), оказывается не многим хуже разрешения рентгеноструктурного анализа, хотя обычно для получения полной информации приходится совмещать разные подходы и, например, “вписывать” структуры отдельных белков в карты электронных плотностей, получаемые при помощи электронной микроскопии.
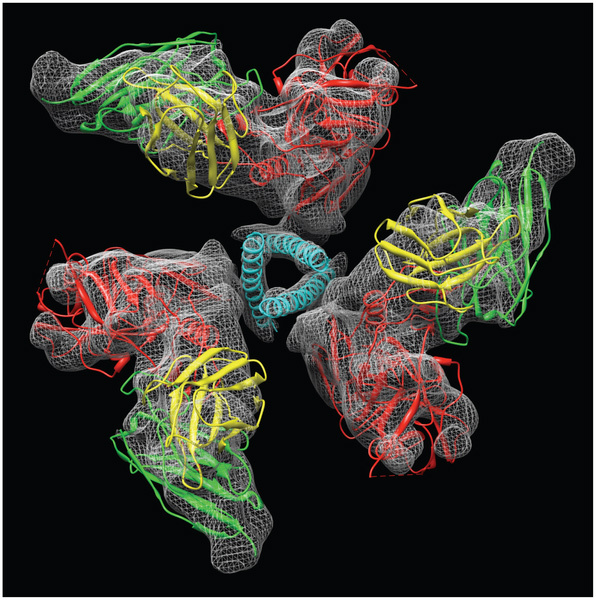 Структуры тримера белка оболочки ВИЧ (красные и голубые фрагменты молекул) в комплексе с участком одного из антител к этому белку (зеленые и желтые фрагменты), вписанные в карту электронной плотности, полученную методом крио-электронной микроскопии с разрешением 9 ангстрем. Из статьи Structural Mechanism of Trimeric HIV-1 Envelope Glycoprotein Activation.
Структуры тримера белка оболочки ВИЧ (красные и голубые фрагменты молекул) в комплексе с участком одного из антител к этому белку (зеленые и желтые фрагменты), вписанные в карту электронной плотности, полученную методом крио-электронной микроскопии с разрешением 9 ангстрем. Из статьи Structural Mechanism of Trimeric HIV-1 Envelope Glycoprotein Activation.
Как мы писали в прошлом посте, получаемые структуры систематизируются и хранятся в базе данных Protein Data Bank. При этом в формате *.pdb записываются координаты атомов, и существует целый набор программ, позволяющих эти данные визуализировать и работать с такими структурами. Среди них, например VMD, Chimera, PyMol и десятки других.
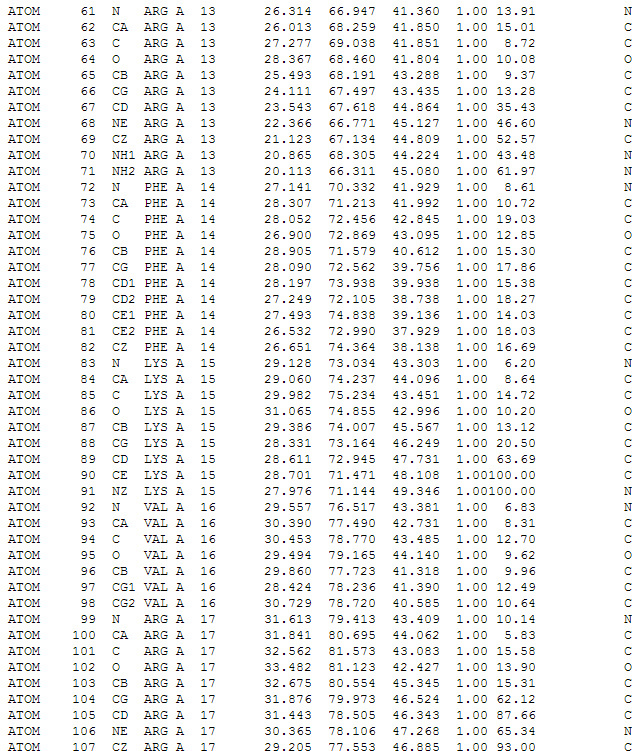 Скриншот текстового отображания файла в формате *.pdb. Описываются координаты отдельных атомов в аминокислотах белка.
Скриншот текстового отображания файла в формате *.pdb. Описываются координаты отдельных атомов в аминокислотах белка.
Программы могут отображать белки несколькими способами. Помимо простого отображения атомов сферами разного диаметра, соответствующего ван-дер-ваальсовым радиусам атомов, существует возможность показать отдельные связи, поверхность молекулы, а также изгибы аминокислотной цепочки при помощи структур, напоминающих ленты (ribbon diagram), которые наглядно демонстрируют, где в белке аминокислоты образуют альфа-спирали, где бета-слои, а где неструктурированные участки.
 Различные варианты визуализации структуры наружней части гемагглютинина вируса гриппа в программе Chimera.
Различные варианты визуализации структуры наружней части гемагглютинина вируса гриппа в программе Chimera.
В качестве отступления, надо сказать, что программы, в которых обычно работают ученые, визуализируя отдельные молекулы или белковые комплексы, чаще всего позволяют получить лишь довольно примитивные с эстетической точки зрения результаты (достаточно, например, посмотреть на несколько скриншотов из программы VMD). Принципиально более широкие возможности открываются, если импортировать модели молекул в программы, которые используют профессиональные дизайнеры и специалисты компьютерной трехмерной графики. Эти программы в сочетании с плагинами, улучшающими качество рендера, позволяют получать действительно интересные и привлекательные визуализации. Мы еще расскажем об этом в следующих постах. Пока просто приведем пример:
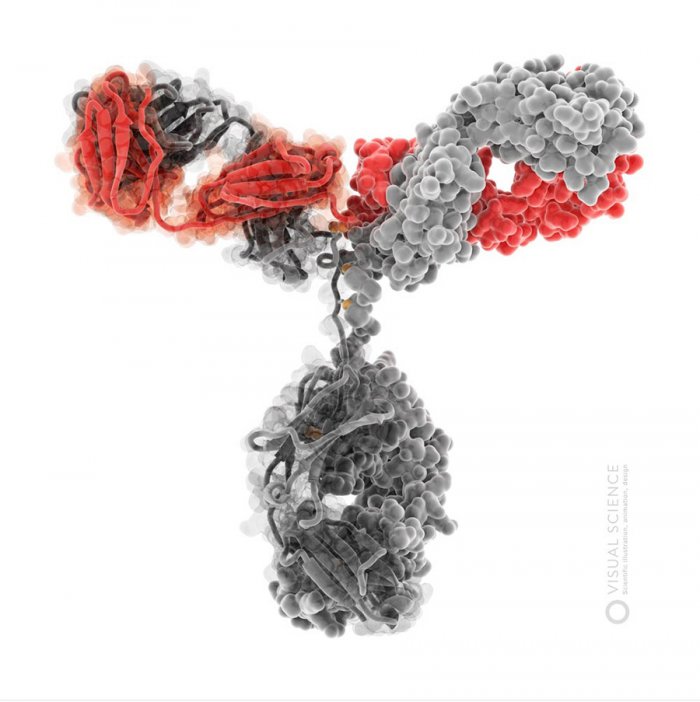
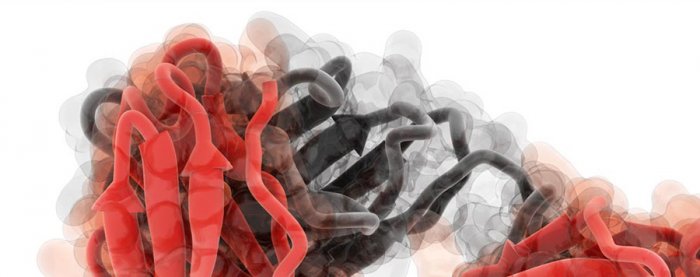 Изображения молекулы иммуноглобулина G
Изображения молекулы иммуноглобулина G
Молекулярное моделирование
Недостающие структуры белков можно попробовать предсказать, что нам и приходится делать для того, чтобы создать полные модели вирусных частиц. Для этого используется ряд компьютерных методов, основанных отчасти на данных о уже описанных структурах, а отчасти — на алгоритмах, позволяющих с определенной достоверностью рассчитать взаимодействия между отдельными атомами молекулы. Моделирование на основе уже известных структур применяется, поскольку современные вычислительные мощности пока не позволяют строить пространственные модели белков исключительно по последовательности аминокислот, исходя из квантово-механических принципов. Плюс, считается, что в настоящее время уже определены укладки такого множества белков, что почти для каждой новой белковой структуры уже есть аналог в банке PDB, главное — его отыскать.
Известно, что белки, у которых одинаковы более 30% аминокислотных остатков, имеют очень сходные структуры. Мы можем найти белок с похожей аминокислотной последовательностью и уже известной структурой, и использовать его в качестве шаблона для построения модели — это называется моделирование по гомологии. Для поиска сходной последовательности обычно используется программа BLAST.
Впрочем, некоторые белки с близкими структурами имеют примерно такое же сходство последовательностей, как и пара случайно выбранных белков. Для того, чтобы найти подходящий шаблон в таких случаях, используют методы Fold recognition. Они «натягивают» последовательность моделируемого белка на разные известные структуры, и оценивают, насколько этот шаблон им подходит. Разные программы используют разные оценочные функции, и поэтому выдают разные результаты. Единого и оптимального алгоритма для Fold recognition сейчас не существует, обычно используют сразу несколько программ и выбирают шаблон, опираясь на все их результаты. Например, можно взять в качестве шаблона белок, имеющий сходную функцию.
Есть методы, которые позволяют собрать модель с использованием сразу нескольких шаблонов, скомбинировав их оптимальным образом. Самый лучший из них называется I-Tasser. Лучшим его объявили не сами создатели программы — уже несколько лет подряд I-Tasser под именем «Zhang-server побеждает в конкурсе по предсказанию белковых структур CASP.
Например, при работе с моделью вируса гриппа мы столкнулись с тем, что одного из поверхностных белков — нейраминидазы, была экспериментально определена только та часть структуры, которая непосредственно выполняет ферментативную функцию (расщепление сиаловой кислоты в составе клеточных мембранных гликопротеинов). Участки молекулы, формирующие “стебель” белка и заякоривающие нейраминидазу в липидной оболочке вируса, пришлось моделировать по гомологии. В качестве шаблонов были взяты описанные структуры гемагглютинин-нейраминидазы вируса парагриппа (3TSI) и одного из трансмембранных пептидов (2LAT).
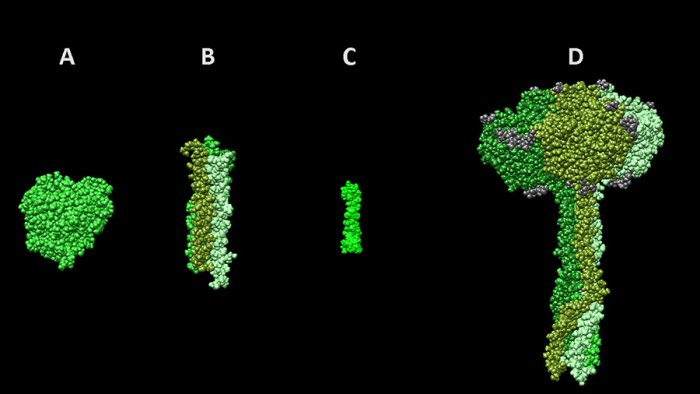 Шаблоны для моделирования нейраминидазного комплекса вируса гриппа. А — фрагмент мономера нейраминидазы N2 из структуры 2AEP в базе данных PDB, B — “стебель” гемагглютинин-нейраминидазы парагриппа (3TSI), С — трансмембранный пептид 2LAT. D — финальная полученная модель.
Шаблоны для моделирования нейраминидазного комплекса вируса гриппа. А — фрагмент мономера нейраминидазы N2 из структуры 2AEP в базе данных PDB, B — “стебель” гемагглютинин-нейраминидазы парагриппа (3TSI), С — трансмембранный пептид 2LAT. D — финальная полученная модель.
Окончательная модель белка обычно создается с учетом известных структур его фрагментов, найденных разными методами шаблонов, а также моделей от сервера I-Tasser. Для этого используется программа Modeller. Она позволяет строить модель по гомологии с использованием одного или нескольких шаблонов, а также вносить дополнительные модификации, например, создавать дисульфидные связи в заданных местах.
Докинг
Другим важным аспектом строения вирусов, информация о котором в научной литературе часто оказывается не полна, является взаимодействие между отдельными белками. В нашем случае от этого зависит то, какими поверхностями модели отдельных белков будут контактировать друг с другом и другими компонентами вириона в финальной модели. Информацию о взаимодействиях тоже позволяет уточнить структурная биоинформатика.
Программа докинга не моделирует естественный процесс образования комплекса, это было бы слишком медленно и ресурсоемко, а перебирает варианты взаимного положения двух или более молекул в поисках наилучшей структуры. При докинге обычно большую молекулу в комплексе называют рецептором, а меньшую — лигандом. Для определения качества структуры комплекса лиганда с рецептором используются различные оценочные функции. В идеале в качестве такой функции должна выступать свободная энергия системы, но она слишком сложно вычисляется, поэтому применяют различные эмпирические псевдопотенциалы, учитывающие потенциальную энергию (которая как раз вычисляется просто), площадь контакта лиганда и рецептора, соответствие различным правилам, которые исследователи вывели из анализа большого числа комплексов, и всякие загадочные слагаемые, не имеющие физического смысла, но улучшающие результат программы при испытании на большом количестве известных комплексов. Поиск минимума такого псевдопотенциала в современных программах обычно происходит с помощью различных вариаций метода Монте-Карло и генетических алгоритмов. В настоящее время существует множество программ молекулярного докинга (наиболее известные из них — Dock, Autodock, GOLD, Flexx, Glide), отличающиеся оценочными функциями, методами минимизации и дополнительными возможностями. При этом во время поиска молекулы рецептора и лиганда могут как оставаться неподвижными (такой тип докинга называется жестким), так и несколько менять конформацию (гибкий докинг). Очевидно, что второй вариант более ресурсоемкий, но и результаты такого поиска обычно правдоподобнее. Докинг малых молекул к белкам сейчас является стандартным этапом разработки новых лекарственных препаратов. Можно, например, провести докинги для 10 миллионов лигандов, и выбрать сотню наиболее перспективных соединений для дальнейшей экспериментальной работы — это называется виртуальный скрининг.
Помимо исследований небольших молекул, докинг может быть использован и для построения белок-белковых и белок-нуклеотидных комплексов. Для этих целей также разработано большое количество программ и онлайн-сервисов (ZDOCK, pyDOCK, HEX). Например, в ходе нашей работы над вирусом папилломы человека (ВПЧ) мы столкнулись с тем, что, несмотря на наличие полной структуры внешнего слоя капсида, образованнного белком L1, совершенно не было информации о строении белка L2, который в капсиде расположен ближе к геному, а соответственно, нет данных о том, как пентамеры L1 взаимодействуют с молекулами L2. Мы построили модель белка L2 по гомологии, используя сервер Tasser, после чего провели докинг в программе HeX. В ходе докинга роль рецептора выполнял пентамер L1. Именно на его поверхности проводился поиск оптимального места посадки L2. При этом все структуры оставались неподвижными. Т.е. использовался метод жесткого докинга. В результате была получена правдоподобная структура комплекса пентамера, собранного из L1 и минорного белка L2.
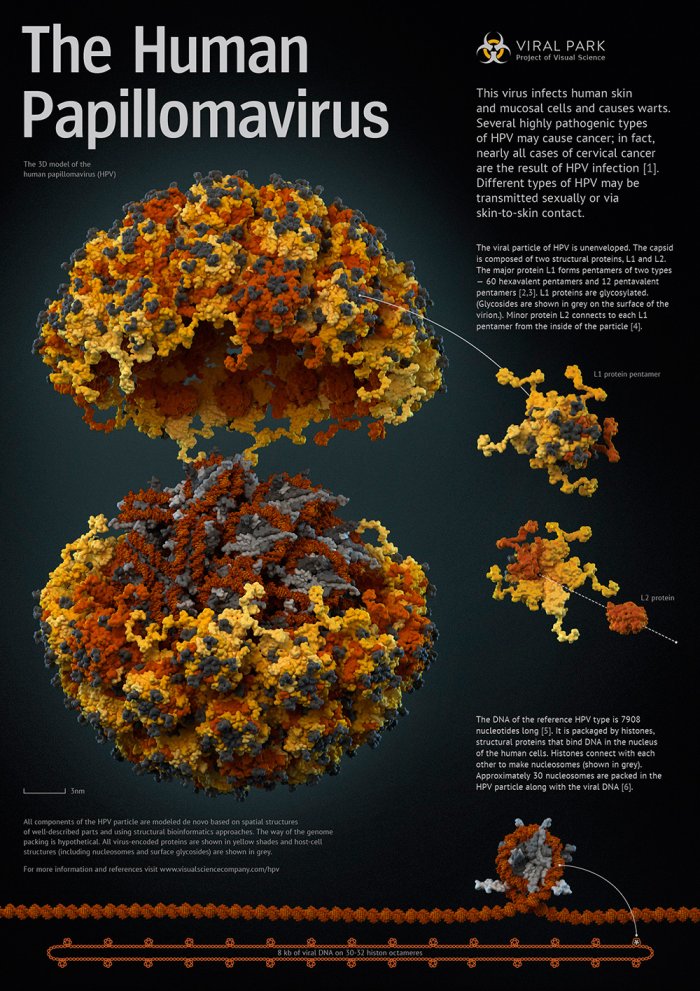 Пентамер основного капсидного белка L1 в комплексе с минорным белком L2 (показан на постере справа от вирусной частицы). Вид «снизу» (разобран) и вид «сверху». Структуры, полученные комбинацией методов моделирования по гомологии и докинга.
Пентамер основного капсидного белка L1 в комплексе с минорным белком L2 (показан на постере справа от вирусной частицы). Вид «снизу» (разобран) и вид «сверху». Структуры, полученные комбинацией методов моделирования по гомологии и докинга.
Посттрансляционные модификации
Наконец, биоинформатическими методами можно пытаться восстановить то, какие изменения в структуру вирусных белков вносит сама клетка, в которой они образуются. Большинство белков после синтеза подвергаются дополнительным химическим посттрансляционным модификациям (ПТМ), которые могут серьезно влиять на выполняемые белком функции. Среди таких модификаций фосфорилирование, убиквитинирование, гликозилирование, нитрозилирование, внесние разрывов и другие химические изменения. Многие поверхностные белки вирусов гликозилированы, причем эта модификация имеет непосредственное значение для выполнения основной функции поверхностных белков вируса — связывания с клеточными рецепторами. С другой стороны, белки вирусных матриксов — слоев, которые встречаются непосредственно под липидными оболочками некоторых вирусов, для заякоривания в мембране часто должны быть связаны, например, с миристиловой кислотой — небольшой гидрофобной молекулой, облегчающей взаимодействие белков с липидами. Таким образом, в нашей работе модификации белков тоже требуют внимания.
В настоящее время возможные ПТМ достаточно сложно предсказываются. Основные существующие методы и сервисы основаны на поиске соответствующей экспериментальной информации для сходных белков или поиске в последовательности исследуемого белка небольших участков, характерных для того или иного типа модификации.
В нашей работе при подготовке моделей мы пользуемся экспериментальной информацией, отраженной в соответствующей записи базы данных UNIPROT.
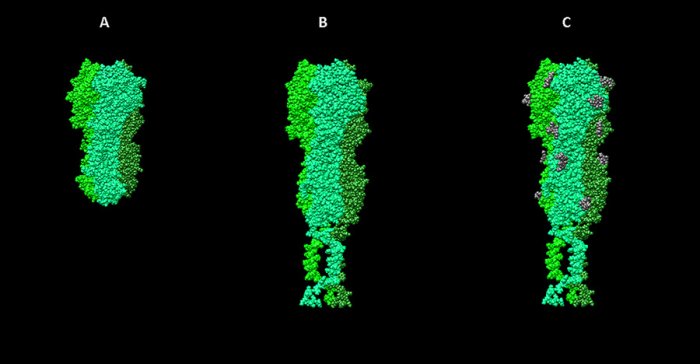 Стадии работы над моделью гемагглютинина вируса гриппа. А — визуализация структуры 3ZTJ из базы данных PDB. B — модель гемагглютинина вируса гриппа H1N1, построенная на основе гомологии с 3ZTJ с достраиванием трансмембранных участков молекулы. С — модель с учетом посттрансляционных модификаций (гликозилирования).
Стадии работы над моделью гемагглютинина вируса гриппа. А — визуализация структуры 3ZTJ из базы данных PDB. B — модель гемагглютинина вируса гриппа H1N1, построенная на основе гомологии с 3ZTJ с достраиванием трансмембранных участков молекулы. С — модель с учетом посттрансляционных модификаций (гликозилирования).
Молекулярная динамика и оптимизация структур
Последнее, о чем хочется упомянуть, — это то, что при подготовке новых моделей белков и, особенно, их комплексов, необходимо проводить оптимизацию структур. Наиболее простым методом оптимизации является минимизация энергии. Она используется для достаточно быстрого “спуска” системы в локальный минимум потенциальной энергии. Эту манипуляцию желательно проводить после каждой модификации структуры молекул. Она позволяет избежать таких неприятностей, как перекрывание атомов или появление неправильных длин связей. Различные методы минимизации энергии предусмотрены практически в любом программном пакете молекулярного моделирования.
Стоит отметить, что данный метод позволяет провести лишь предварительную и очень грубую оптимизацию. Для более точной подготовки пространственных структур используются методы молекулярной динамики или квантовой механики. Последние, например, используются для наилучшей оптимизации структуры небольших молекул лигандов и наиболее точных расчетов энергии межмолекулярных взаимодействий. Но, наибольшая точность, что вполне логично, связана с более ресурсоемкими вычислениями, что делает эти методы практически неподъемными в применении к большим биологическим макромолекулам. Оценить поведение и стабильность структур достаточно массивных молекул, таких как полипептиды и нуклеиновые кислоты позволяют методы молекулярной динамики.
Метод молекулярной динамики заключается в изучении поведения атомов и молекул и их движений во времени. Расчеты молекулярной динамики позволяют, например, исследовать стабильность как отдельных молекул, так и их комплексов, позволяют оценить значимость возможных конформационных перестроек, влияние точечных мутаций и многое другое. Современные методы анализа результатов симуляций молекулярной динамики позволяют получить самые подробные сведения о поведении во времени как отдельных атомов, так и всей исследуемой системы.
В зависимости от того, насколько хорошо изучены белки того вируса, модель которого мы хотим создать, каждый раз приходится подбирать подходы для достройки и оптимизации моделей всех белков и их взаимодействий. После того, как все структуры получены, можно приступать к сборке полной модели. О том, как это делается, мы расскажем в следующих постах серии о создании научно достверных моделей вирусов человека.
PS:
Ставшая лидером в опросе прошлого поста тема Медицинская анатомическая иллюстрация — история изучения тела человека в работах иллюстраторов 5 столетий будет следующей. С потрясающими гравюрами, восковым моделями прошлого века, пластификатами трупов, атласами выдающся исследователей, 3Д реконструкциями на основе послойных срезов замороженного смертника, интерактивными приложениями и работами современных медицинских иллюстраторов. Скоро.
- Источник(и):
- Войдите на сайт для отправки комментариев
