Компьютерное зрение в промышленности. Лекция в Яндексе
Друзья, с момента основания проекта прошло уже 20 лет и мы рады сообщать вам, что сайт, наконец, переехали на новую платформу.
Какое-то время продолжим трудится на общее благо по адресу
На новой платформе мы уделили особое внимание удобству поиска материалов.
Особенно рекомендуем познакомиться с работой рубрикатора.
Спасибо, ждём вас на N-N-N.ru
Машинное обучение продолжает проникать в индустрии за пределами интернет-отрасли. На конференции Data&Science «Мир глазами роботов» Александр Белугин из компании «Цифра» рассказал об успехах, сложностях и актуальных задачах на этом пути. Внедрение таких технологий, как компьютерное зрение, требует серийности и продуктового подхода, позволяющего снизить стоимость единичных внедрений. Дело в том, что видов задач на производстве очень много. Из доклада можно узнать о продуктах, мировых трендах и опыте команды Александра в сферах промышленной безопасности и автоматизации процессов.
— Доброе утро. Рад, что все пришли на эту интересную конференцию. Я сначала кратко расскажу про компанию «Цифра», затем — немного о задачах, которые стоят в промышленности, и о типовых способах решения таких задач. Это задачи без роботов, не сборочные, а разные процессные производства. В конце немного рассмотрим наш опыт.

Мы уже год работаем на рынке и своей целью видим полную автоматизацию промышленных производств, что позволит достичь 10–15-процентного повышения их прибыльности. Чтобы сделать это полностью, нужно решать все задачи, заканчивая какой-то совместной оптимизацией всех процессов, логистики, закупок и самого производства, но начиная с таких базовых вещей, как интернет вещей, датчики, сбор информации.

Сейчас это называется модным словом цифровизация. Это перенос данных обо всех процессах в цифровую форму, чтобы потом можно было их использовать для повышения эффективности.

Сегодня мы больше говорим про компьютерное зрение. Есть еще термин «машинное зрение», который относится к технике. Есть видеокамеры, похожие на те, которые используются для видеонаблюдения, есть веб-камеры, которые используются для коммуникаций, а есть специальные камеры в промышленности. Они отличаются тем, что у них часто нет обычного Ethernet-порта, применяются специальные протоколы, они могут передавать, например, 750 кадров в секунду и не в режиме burst, а непрерывно, без сжатия. Есть специальные камеры с особой светочувствительностью и в других диапазонах, чем оптически видимые глазу. Есть даже камеры, которые считывают одну полосу, делают очень много кадров в секунду, но шириной в один пиксель. Такая камера стоит над конвейером и смотрит, что там происходит.
Отличительной особенностью задач компьютерного зрения является то, что на выходе должна быть не картинка — она никого не интересует, — а число, которое характеризует качество или размеры того, что мы наблюдаем.

Хочу перечислить несколько основных задач. Первый крупный блок — это то, что связано с безопасностью. Есть контроль периметра, чтобы ничего не вынесли с предприятия. Это пример из числа задач видеоаналитики, которые уже 15–20 лет решаются, с каждым годом все лучше. Если есть забор и видеокамера и кто-то пытается перелезть, то видеоаналитика его поймает точно.
Есть более сложные задачи — контроль перемещения по каким-то зонам. Например, на предприятии всегда можно обжечься, оказаться в зоне разгрузки-погрузки или на путях, где ездят тележки. Тут уже более сложная задача, надо соблюдать узкие ограничения, понимать, по каким дорожкам могут ходить люди.
Еще один пример задачи, связанной с безопасностью, — детекция касок на головах, когда ставят камеры на площадках. В России эта тема очень плохо продается. Когда люди слышат, сколько такие системы стоят, они говорят, что у нас же есть регламент, человек должен каску надеть и он ее наденет, а если нет — нарушил регламент, его проблема. В целом в мире это популярное решение, которое продвигают и вендоры, и частные компании.
Следующий блок задач связан с учетом. В основном это распознавание каких-то наклеек. Бывают специальные наклейки, когда печатают штрихкод. Тогда это чуть легче работает. Есть куча готового ПО по распознаванию штрихкодов или отчетливо напечатанных символов. Часто пытаются сэкономить, не менять систему кодирования, а использовать компьютерное зрение для распознавания. Тогда это могут быть, например, набитые на железнодорожном вагоне и плохоразличимые числа. Тогда все сложнее, нужно тратить больше времени на строительство всего этого. Это нужно для борьбы с хищениями и для контроля товаров — что поступило на предприятие, как оно перемещалось внутри него и куда в итоге вышло.

Последний блок задач — контроль качества. Его тоже можно разбить на две составляющие. Одна связана с физическим контролем качества. Можно смотреть размеры тех или иных объектов. Чаще всего это касается мелочей: какие-то крышечки от пакетов с молоком или от бутылок. У них довольно простой дешевый процесс производства, много брака, их надо просто отфильтровывать, делать их более качественными невыгодно.
И есть часть, которая на картинке. Тут уже более сложные задачи. Это когда мы пытаемся понять — а правильное ли, вообще-то, действие совершают с нашим товаром. Например, нужно оценить позу механика и понять, какую операцию он выполняет. Или была задача, когда есть площадка, на которой собирают и разбирают буровые установки. Юольшое месторождение, собирают установки, везут работать, потом разбирают и увозят. Сажать человека на север отслеживать эти операции очень дорого, при том что он будет простаивать большую часть времени. По видеокамере тоже. По видеокамере можно смотреть автоматически, какие события происходят, и отслеживать график сборки и разборки.

Еще пример — скриншот партнерского софта, контроль браков в отливках, всякие пластиковые штучки до того, как покрасит, вот так выливают в таких формах. Можно детектировать брак с помощью камеры.
Есть два основных подхода к решению этих задач. Оба придуманы давно, но классический состоит в том, чтобы какими-то алгоритмами работать над изображениями.

Слева рычаг, попытка его обозначить. Справа уже не так понятно. Круги — это рулоны стальных листов свернуты, по центру непонятно что. Методы в том, чтобы как-то обработать изображение, повысить его контрастность, может, сделать его двухцветным, выделить какие-то грани, edges объектов, пытаться найти сами объекты, и дальше с ними работать.

Второй способ, более современный, относящийся к data science, все что связано с нейросетями. Здесь есть определенные преимущества. Первое и главное, что по качеству удается достичь более высоких результатов в большинстве сложных задач, которые классическими методами не решаются. Некоторые примеры задач перечислены.
Есть адаптивность, можно настроить алгоритм обучения нейросети, и переносить с задачи на задачу не саму обученную нейросеть, но все вместе с алгоритмом, и тогда немного разные задачи можно решить одним и тем же инструментом.
Есть минусы, которые часто играют в промышленности — недостаток данных. Чтобы начать выявлять дефекты, если мы говорим про классические методы, нам нужен видеопоток, который снимает готовую продукцию, нужно посмотреть, какие там дефекты, глазами, увидеть их и заставить наш код их видеть. Перебрать несколько параметров, не требуется ручной разметки для этого. В случае с нейросеткой нужно большое количество примеров, либо собирать их вручную, либо использовать современные хитрые методы, чтобы их генерировать. Это долгий и сложный процесс, который, может, еще нужно повторять из раза в раз при переносе на другие задачи.

Здесь пример такой картинки, связанной с детекцией дефектов. Одна из популярных тем, если смотреть, какие есть статьи, на нижней части картинки показан маленький брак на конструкциях. С использованием нейросетей можно выявлять от 92% до 99% всех дефектов, на разных работах по-разному, при ложных срабатываниях на уровне 3–4%, вполне пригодные результаты. Нормальный уровень брака на разных производствах от 0,5% до маленьких единиц процентов. Такие показатели вполне подходят, чтобы заменить человека, который обнаруживает эти дефекты. Или еще улучшить результаты.

Еще пример задач, связанных с цифровизацией, подключением разного оборудования, у которого нет цифровых интерфейсов, где зеленая стрелка — это рычаги. Небольшой кадр с рабочего места бурильщика, который управляет бурением, у него есть какие-то рычаги, которые он переключает. Бурение — это важно, дорогостоящий процесс, пару миллионов рублей в сутки. И это никак не регистрируется, он какие-то рычаги переключает, и нигде нет записи, либо в лучшем случае она в ручном журнале, какие шли переключения этих рычагов. Это критически важно.

Это печь, которая закаляет проволоку. В данном примере проволока из золота. Печке где-то 25 лет, внутрь заходит чистое золото, расплавляется, льется в тонкую нить, и теплом закаляется, обжигается, превращается в твердый материал. Известно, что дальше иногда эта проволока получается надежной, из нее сплетают всякие цепочки, а иногда некоторое количество проволоки приводит к браку, во время плетения цепочек они ломаются, трескаются, рвутся. Кажется, что это зависит от режимов термообработки с учетом того, что сырье немного меняется. Здесь написано data logger, справа за кадром есть самописец, который на рулон бумаги может писать свои параметры. Здесь три параметра: температура в чашке, в которой расплавляется золото, температура нагрева — режим печи, и скорость, с которой все это проходит.
Чтобы понять, с чем связан брак и можно ли настроить печку так, чтобы брак снизить, эти параметры нужно оцифровать. Как? У нее есть промышленные разъемы, но это все было 25 лет назад, будет стоить очень дорого, либо реверсивным инженирингом сделать подключение, либо заплатить производителю печи, если компания еще не разорилась, за подключение. Подключение такого оборудования к УТП или MS-системе [00:14:24] может стоить, например, миллион рублей. А может, сотни тысяч. Особенно учитывая то, что таких печей всего две, не сто.

Как можно решить эту задачу инструментами, о которых мы говорили? Классический подход с помощью OpenCV в данном случае не работает, слишком много бликов, изображение нечеткое, даже человек не особо различает, какие там числа. OCR, готовые библиотеки для распознавания текста тоже не очень подходят.
Остается второй вариант — нейросети. В данном случае он работает, но предусматривает большое количество шагов. Наверняка нужно собрать какую-то разметку для обучения сети, тестирования, подобрать какую-то сеть, обучить ее. Это все нужно сделать, протестировать. Я прикинул трудозатраты. Тут можно дискутировать, можно быстрее сделать или медленнее, но в целом получается 72 часа. По ставке хорошего специалиста это может стоить столько. При этом мы не получили ни инфраструктуры, ни ПО. Мы просто получили настроенную и протестированную сеть, которая хорошо распознает эти числа.
Плюс подхода — оно работает. Минус — так тоже никто не готов внедрять. Сначала нужно научиться собирать эти данные, и только потом понять, действительно ли есть взаимосвязь этих данных с браком. Если есть, надо придумать, как и что поменять, чтобы снизить долю брака. Что если ее слишком много? А заплатить за пилот, за автоматизацию и подключение, сходу надо минимум столько. Даже, скорее всего, больше.

Поэтому за последние три года на нашем опыте таких проектов не удалось продать ни одного. Если это брак трубы, где стоит человек, то человек стоит гораздо дешевле. Если это сложная вещь, то слишком велики риски для заказчиков. Вывод — нужно это продуктизировать.
Сейчас в мире, на рынках машинного обучения есть много движения в сторону продуктовизации. Всякие auto ML решения, которые позволяют частично заменить дата-саентиста, и готовые продукты или решения для конкретных применений. Самый простой пример — рекомендации в e-сommerce. Давно есть продукты, где в стандартном формате подключаются данные, и они сами выдают рекомендашки. Мы постарались сделать то же самое в области компьютерного зрения. Предложить продукт, который позволяет автоматизировать и на порядок снизить ручной труд для подключения старого оборудования с распознаванием чисел: стрелочных индикаторов и других.

Первая задача, которую надо решить, — сократить затраты на настройку. Когда поставили камеру, надо позволить людям выделить зону интереса. Например, вот так обвести прямоугольником и сказать, что хочу распознавать в этой зоне.
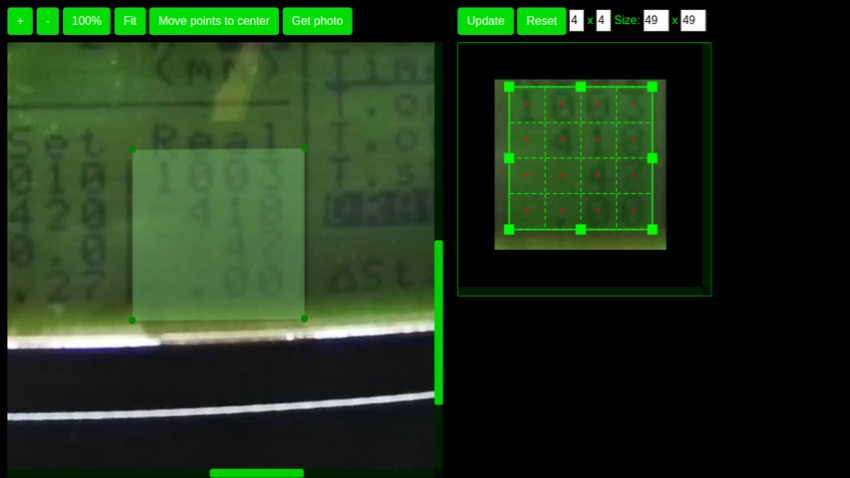
Дальше вопрос, что все задачи разные, и как раз в этом месте нужно учить какие-то нейросети, чтобы они хорошо работали именно тут.

Ссылка со слайда
Мы знаем, что есть разные нейросети. Если говорить про числа, в смартфонах у многих есть автопереводчики: наводим на любой текст, и он более-менее начинает его переводить, независимо от шрифта или угла. Такие решения есть, а значит, и с помощью табло можно натренировать сеть, которая будет работать хорошо с любыми табло. Но у нее будут минусы — она будет тяжелая, сложная, будет работать медленно, и поскольку она универсальная, будет страдать качество на конкретной задаче. Поэтому мы использовали подход, который называется Tutor-Student, при котором в решение встраивается набор мощных сетей для конкретных задач. Например — отдельно для текстов, для каких-то рычажков, для стрелочных индикаторов. Существует не так много видов подобных приборов. Эта система работает сама, распознает что-то, а затем дает оператору возможность произвести доразметку, проглядеть глазами и исправить 3–5% ошибок, которые он увидит. И затем на основе такой экспресс-методом сгенерированной разметки обучить уже легковесную сеть, которая адаптирована под конкретную задачу заказчика, под его данные. Такой подход позволяет существенно сократить затраты на внедрение, при этом сделать качество почти таким же, как если бы работа шла руками.

Легковесная сеточка нужна затем, что не везде на предприятиях есть возможность подключить видеокамеры к какой-то системе управления видео. Если бы была такая VMS, то можно все делать на сервере, где ограничение по ресурсам связано только со стоимостью. А есть еще чипы, встроенные в видеокамеру наподобие Nvidia Jetson, и отдельные решения. В частности, наше решение работает на Orange PI, это разновидность микрокомпьютера Raspberry PI, и выдает 8–10 кадров в секунду, получая на вход Full HD-картинку.

Дальше тоже продуктовая часть. Все эти данные нужно куда-то класть. Здесь сразу предусмотрен набор стандартных коннекторов.

Подведем итоги. Такая продуктивизация позволяет двигать машинное обучение и компьютерное зрение в массы, на широкий рынок, за счет низкой стоимости и небольших затрат на внедрение, без использования дорогих специалистов и дата-саентистов. Думаю, за этим будущее, в том числе и в промышленности.
- Источник(и):
- Войдите на сайт для отправки комментариев
