Grasp2Vec: обучение представлению объектов через захват с самостоятельным обучением
Друзья, с момента основания проекта прошло уже 20 лет и мы рады сообщать вам, что сайт, наконец, переехали на новую платформу.
Какое-то время продолжим трудится на общее благо по адресу
На новой платформе мы уделили особое внимание удобству поиска материалов.
Особенно рекомендуем познакомиться с работой рубрикатора.
Спасибо, ждём вас на N-N-N.ru
Люди с удивительно раннего возраста уже способны распознавать свои любимые объекты и поднимать их, несмотря на то, что их специально этому не учат. Согласно исследованиям развития когнитивных способностей, возможность взаимодействия с объектами окружающего мира играет критическую роль в развитии таких способностей, как ощущение и манипулирование объектами – к примеру, целенаправленный захват.
Взаимодействуя с окружающим миром, люди могут учиться, исправляя собственные ошибки: мы знаем, что мы сделали, и учимся на результатах. В робототехнике такой тип обучения с самостоятельным исправлением ошибок активно исследуется, поскольку он позволяет роботизированным системам учиться без огромного количества тренировочных данных или ручной подстройки.

Мы в Google, вдохновившись концепцией постоянства объектов, предлагаем систему Grasp2Vec – простой, но эффективный алгоритм построения представления объектов. Grasp2Vec основан на интуитивном понимании того, что попытка поднять любой объект выдаст нам некоторую информацию – если робот захватит объект и поднимет его, то объекту нужно находиться в этом месте до захвата. Кроме того, робот знает, что если захваченный объект находится в его захвате, то, значит, объекта уже нет на том месте, где он был. Используя такую форму самостоятельного обучения, робот может научиться распознавать объект благодаря визуальному изменению сцены после его захвата.
На основе нашего сотрудничества с X Robotics, где несколько роботов параллельно обучались захватывать объекты домашнего обихода, используя только одну камеру в качестве источника входных данных, мы используем роботизированный захват для «ненамеренного» захвата объектов, и этот опыт позволяет получить богатое представление об объекте. Это представление можно использовать уже для приобретения способности «намеренного захвата», когда рука робота может поднимать объекты по требованию.
Создание функции перцепционной награды
На платформе обучения с подкреплением успех задачи измеряется через функцию награды. Максимизируя награду, роботы обучаются различным навыкам захвата с нуля. Создать функцию награды легко, когда успех можно измерить простыми показаниями датчиков. Простой пример – кнопка, передающая по нажатию на неё награду непосредственно на вход роботу.
Однако создание функции награды куда как сложнее, когда критерий успеха зависит от перцепционного понимания задачи. Рассмотрим задачу захвата на примере, когда роботу дают изображение нужного объекта, удерживаемого в захвате. После того, как робот пытается захватить объект, он изучает содержимое захвата. Функция награды для этой задачи зависит от ответа на вопрос распознавания образов: совпадают ли объекты?
 Слева захват держит щётку, а на фоне видно несколько объектов (жёлтая чашка, синий пластиковый блок). Справа захват держит чашку, а щётка находится на фоне. Если бы левое изображение представляло нужный результат, хорошая функция награды должна была бы «понимать», что эти две фотографии соответствуют двум разным объектам.
Слева захват держит щётку, а на фоне видно несколько объектов (жёлтая чашка, синий пластиковый блок). Справа захват держит чашку, а щётка находится на фоне. Если бы левое изображение представляло нужный результат, хорошая функция награды должна была бы «понимать», что эти две фотографии соответствуют двум разным объектам.
Чтобы решить задачу распознавания, нам нужна перцепционная система, извлекающая осмысленные концепции объектов из неструктурированных изображений (не подписанных людьми), и обучающаяся визуальному восприятию объектов без учителя. По сути, алгоритмы обучения без учителя работают, создавая структурные предположения по поводу данных. Часто предполагается, что изображения можно сжать до пространства с меньшим количеством измерений, а кадры видео можно предсказать по предыдущим. Однако без дополнительных предположений по поводу содержимого данных этого обычно не хватает для обучения по ни с чем не связанным представлениям объектов.
Что, если бы мы использовали робота для того, чтобы физически отделить объекты во время сбора данных? Робототехника предлагает прекрасную возможность для обучения представлению объектов, поскольку роботы могут ими манипулировать, что даст необходимые факторы вариации. Наш метод основан на идее о том, что захват объекта устраняет его со сцены. В результате получается 1) изображение сцены до захвата, 2) изображение сцены после захвата, и 3) отдельный вид на захваченный объект.
 Слева — объекты до захвата. В центре – после захвата. Справа – захваченный объект.
Слева — объекты до захвата. В центре – после захвата. Справа – захваченный объект.
Если мы рассмотрим встроенную функцию, извлекающую из изображений «набор объектов», она должна сохранять следующее соотношение вычитания:
 объекты до захвата – объекты после захвата = захваченный объект
объекты до захвата – объекты после захвата = захваченный объект
Мы достигаем этого равенства при помощи свёрточной архитектуры и простого алгоритма метрического обучения. При тренировке показанная ниже архитектура встраивает изображения до и после захвата в плотную карту пространственных свойств. Эти карты превращаются в вектора через усреднённое объединение, и разница между векторами «до захвата» и «после захвата» представляет набор объектов. Этот вектор и соответствующее ему представление вектора этого воспринятого объекта приравниваются через функцию N-пар.
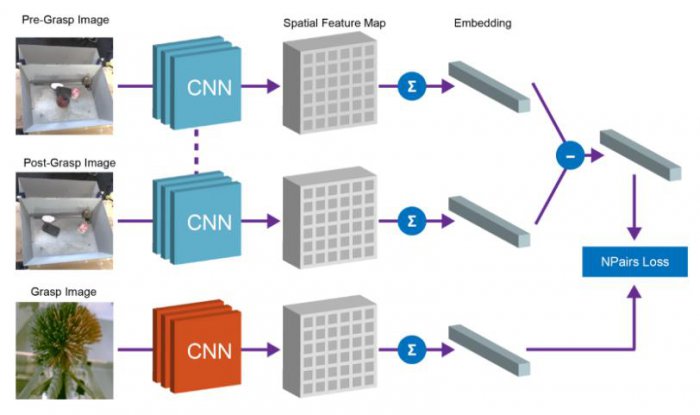
После тренировки у нашей модели естественным образом появляются два полезных свойства.
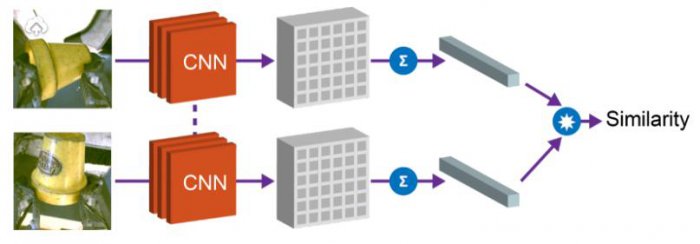
1. Схожесть объектов
Косинусный коэффициент расстояния между векторными встройками позволяет нам сравнивать объекты и определять, идентичны ли они. Это можно использовать для реализации функции награды для обучения с подкреплением, и позволяет роботам обучаться захвату на примерах без разметки данных людьми.
2. Нахождение целевых объектов
Мы можем комбинировать пространственные карты сцены и встройку объектов для локализации «нужного объекта» в пространстве изображения. Осуществляя поэлементное перемножение карт пространственных особенностей и векторного соответствия нужного объекта, мы можем найти все пиксели на пространственной карте, соответствующие целевому объекту.
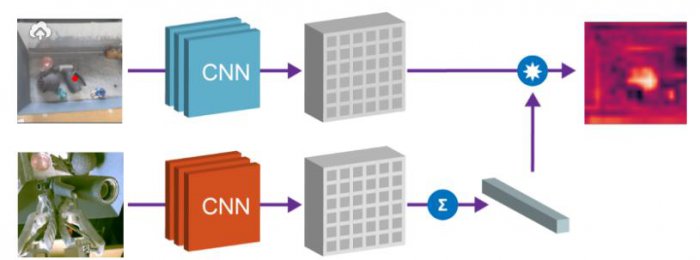 Использование встроек Grasp2Vec для локализации объектов в сцене. Слева вверху – объекты в корзине. Слева внизу – нужный объект, который надо захватить. Скалярное произведение вектора целевого объекта и пространственных особенностей изображения даёт нам попиксельную «карту активации» (справа вверху) похожести заданного участка изображения на целевое. Эту карту можно использовать для приближения к целевому объекту.
Использование встроек Grasp2Vec для локализации объектов в сцене. Слева вверху – объекты в корзине. Слева внизу – нужный объект, который надо захватить. Скалярное произведение вектора целевого объекта и пространственных особенностей изображения даёт нам попиксельную «карту активации» (справа вверху) похожести заданного участка изображения на целевое. Эту карту можно использовать для приближения к целевому объекту.
Наш метод также работает, когда несколько объектов соответствуют целевому, или даже когда цель состоит из нескольких объектов (среднее из двух векторов). К примеру, в данном сценарии робот определяет несколько оранжевых блоков в сцене.
 Получающуюся «тепловую карту» можно использовать для планирования приближения робота к целевому объекту (объектам). Мы комбинируем локализацию от Grasp2Vec и распознавание примеров с нашей политикой «захвата всего, что угодно», и достигаем успеха в 80% случаев во время сбора данных и в 59% с новыми объектами, с которыми робот ранее не сталкивался.
Получающуюся «тепловую карту» можно использовать для планирования приближения робота к целевому объекту (объектам). Мы комбинируем локализацию от Grasp2Vec и распознавание примеров с нашей политикой «захвата всего, что угодно», и достигаем успеха в 80% случаев во время сбора данных и в 59% с новыми объектами, с которыми робот ранее не сталкивался.
Заключение
В нашей работе мы показали, как навыки роботизированных захватов могут создать данные, используемые для обучения представлениям объектов. Затем мы можем использовать обучение представлению для быстрого получения более сложных навыков, типа захвата по примеру, при этом сохраняя все свойства обучения без учителя в нашей автономной системе захвата.
Кроме нашей работы, в нескольких других недавних работах также проводилось изучение того, как взаимодействие без учителя можно использовать для получения представлений объектов, путём захвата, толчков и другого рода взаимодействий с объектами в окружении. Мы находимся в радостном предвкушении не только того, что машинное обучение может дать робототехнике в плане лучшего восприятия и контроля, но и того, что робототехника может дать машинному обучению в плане новых парадигм самостоятельного обучения.
Автор: Вячеслав Голованов
- Источник(и):
- Войдите на сайт для отправки комментариев
