Роботы в журналистике, или Как использовать искусственный интеллект для создания контента
Друзья, с момента основания проекта прошло уже 20 лет и мы рады сообщать вам, что сайт, наконец, переехали на новую платформу.
Какое-то время продолжим трудится на общее благо по адресу
На новой платформе мы уделили особое внимание удобству поиска материалов.
Особенно рекомендуем познакомиться с работой рубрикатора.
Спасибо, ждём вас на N-N-N.ru
Машины становятся умнее. Уже сейчас они генерируют контент такого качества, что даже профессионал не всегда отличает его от «человеческого». О том, почему журналистам и редакторам не стоит опасаться конкуренции, и о перспективах автоматизации журналистики на конференции «Контентинга» рассказал Сергей Марин из «Студии данных».
О спикере: Сергей Марин — эксперт по искусственному интеллекту, руководитель и основатель «Студии данных».
Три кита искусственного интеллекта
Если мы говорим об искусственном интеллекте – в журналистике или в любой другой сфере – нужно, прежде всего, понять его устройство. Состоит ИИ из трех основных компонентов: машинного обучения, рекомендательных систем и нейросетей. Кстати, многие считают нейросети синонимом искусственного интеллекта, но это лишь один из инструментов, даже не самый массовый: в каждом случае используются те алгоритмы, которые работают наиболее оптимально.
Машинное обучение: разложить по полочкам
Машинное обучение применяют для поиска скрытых закономерностей в данных. Представим, что у нас есть набор инфоповодов или публикаций, которые нужно классифицировать, то есть автоматически присвоить им какие-то теги. Или просто тексты с большим количеством слов, которые необходимо разделить на некие классы, интересы, настроения и так далее. Как мы это делаем? Если говорить о машинном обучении, то мы не ищем какие-то ключевые слова, чтобы сделать выводы на их основе. Вместо этого мы показываем машине как можно большее количество уже размеченных нами текстов с большим количеством классов. После чего даем новый текст, и машина уже сама классифицирует его в область, к которой он относится. То есть мы сначала обучаем, показываем много примеров.

То есть главное применение машинного обучения в журналистике – классификация. Например, у нас есть большое количество инфоповодов – из интернета, соцсетей, новостных агентств – и нам нужно быстро их классифицировать. Мы заранее обучили нашу модель, и когда у нас появляется новый инфоповод, машина понимает, куда он относится, какая его тематика, какое настроение он передает, для какой аудитории его можно применить. Аналогично прогнозируется популярность, рейтинг какого-то инфоповода.
Рекомендательные системы: найти персональный подход
Основная область применения рекомендательных систем – персонализация. Мы хотим показывать контент, который актуален как минимум для некоего сегмента, а в идеале – подбирать его под каждого человека. В этом плане презентация контента не отличается от продаж. Вспомним лидеров по продажам таргетированных продуктов: онлайн-магазины вроде «Амазона» и онлайн-кинотеатры умеют рекомендовать свои товары. И если рассматривать контент как продукт, то выходит, что мы уже умеем его хорошо рекомендовать и таргетировать.

Как мы это делаем? Есть два базовых принципа. Первый – рекомендательные системы, которые по факту сравнивают людей между собой на основе их покупок, в данном случае – по контенту, который они потребляли ранее. Возьмем простой пример: Игорь и Петр просмотрели примерно одни и те же фильмы, и если один из фильмов просмотрен только Игорем, то логично рекомендовать его Петру.
Другой принцип гораздо сильнее с точки зрения рекомендации контента – оценка его популярности, PageRank. Первый такой пример – поиск, выдача в Яндексе, Гугле. Как определить, что некая страница является значимой? Мы считаем количество ссылок или упоминаний данной страницы на других ресурсах и получаем своеобразный рейтинг, который присваивается ей. Но одно дело, когда на публикацию ссылаются пять неизвестных страниц, и совсем другое, если ссылки дают популярные бренды или крупные новостные агентства. Выходит, что надо учитывать рейтинг тех, кто ссылается на нашу страницу – получается такая иерархия.
Точно так же работает Tinder: когда вы листаете влево-вправо, то рейтинг вычисляется и для вас, и для тех людей, которых вам показывают. Вам демонстрируют фото тех, у кого примерно одинаковый с вами рейтинг – в этом заключается рекомендательный смысл сервиса.

Это очень эффективный метод автоматизированной оценки значимости некой информации. Если вы умеете считать не только упоминания, но и их значимость, вы можете автоматически отсортировать все инфоповоды для определенных целевых аудиторий. Поэтому рекомендашки используются в основном для такого таргетирования на уровне.
Нейросети: подражание мозгу
Концепция нейросетей простая и скучная. Примерно до 60-х годов прошлого века исследования принципов работы человеческого мозга рисовали следующую картину: есть некий набор нейронов, получающих сигналы на входе. После этого каждый нейрон производит небольшую модификацию сигнала и передает его дальше. Чтобы понять, как эти нейроны объединяются в группы внутри мозга, решили создать компьютерную модель – набор нейронов, которые между собой как-то связаны. Так зародились первые нейросети, и в таком виде они до сих пор используются для решения задач машинного обучения. Но если мы говорим о чем-то более продвинутом, то такая система не подходит.
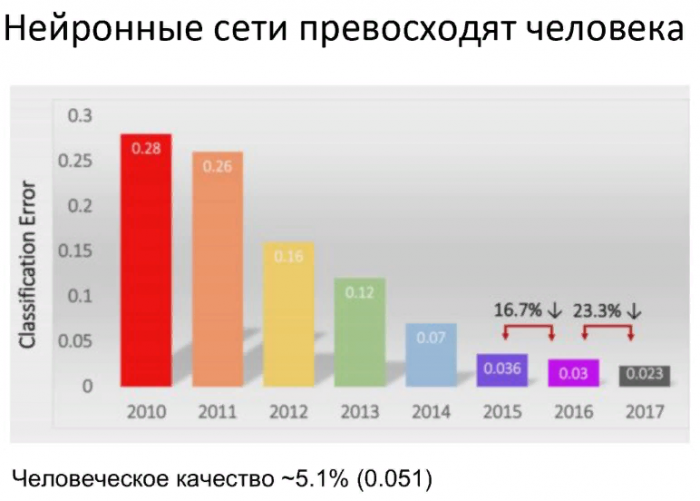
Где-то в 90-х годах прошлого века ученые поняли, что человеческий мозг работает не совсем так. Нейроны действительно взаимодействуют между собой, но все построено иерархично. Например, когда я вижу картинку, то из каждой ее области собирается информация, которая дальше агрегируется на другую, меньшую группу нейронов. И там она хранится в виде какого-то внутреннего представления. На самом деле, мы мыслим этими внутренними представлениями, а не реальными картинками, которые видим. Теорию сразу воссоздали в нейросетях, и сейчас по классификации изображений такие нейросети работают значительно лучше человека. Называются эти нейросети сверточными – потому что происходит процесс обобщения.
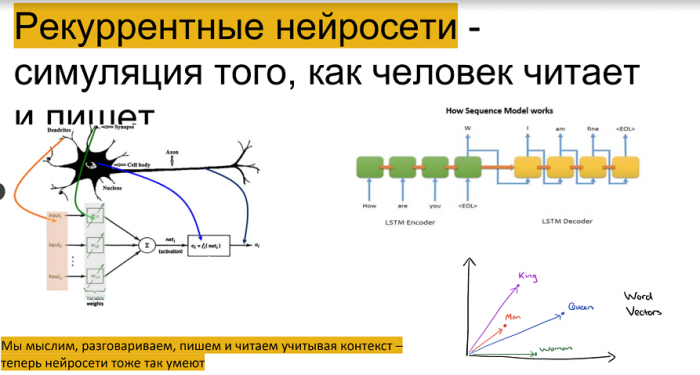
Второй прорыв произошел, когда выяснили: человек воспринимает информацию не в моменте, а с учетом некого контекста. Чтобы обучить компьютеры анализировать накопленный опыт, построили так называемые рекуррентные нейросети. Они используют работу предыдущих нейросетей сначала для классификации, а потом для создания некоего контента. Это все используется сейчас в Sequence Modeling, а если проще – в чат-ботах. Например, когда Яндекс подбирает похожие слова – это рекуррентные нейросети, реплицирующие то, как человек обрабатывает информацию.
Как применяют нейросети в журналистике
Первая область применения нейросетей – генерация контента. Если у нас есть некий инфоповод, то обученная нейросеть позволяет определить тематику и написать вполне внятный текст. Уже появились компании, которые производят соответствующий софт. Есть издания, которые используют его для рутинных инфоповодов – биржевых сводок, финансовых показателей компаний. Для фактической информации – здесь прошло землетрясение, там проплыл корабль и так далее – это работает отлично. Но если речь идет о более продвинутых инфоповодах, то придется серьезно поработать, чтобы преобразовать сгенерированный нейросетью контент во что-то действительно содержательное и адекватное.

Вторая сфера – классификация, о ней уже сказано выше. Третья – оценка восприятия или А/Б тестирование, которое редко используется где-то за пределами продаж. В журналистике принцип аналогичен: у нас есть несколько форм публикации, и мы хотим протестировать – как она зайдет в разных целевых группах. С помощью подобного рода методов этот процесс можно полностью автоматизировать.
Последнее направление понравится тем, кому нужно писать один и тот же контент для разных каналов, ресурсов, целевых аудиторий. Чтобы опубликовать на Хабре статью, которая уже вышла в другом издании, нельзя делать просто copy-past. Для ее адаптации можно либо привлечь копирайтера, либо применить нейросеть. Для компьютера это даже проще чем машинный перевод: текст не нужно преобразовывать в другой язык, синтаксис и так далее. Но в целом все то же самое.
Где используется? Пионер среди крупных агентств – Associated Press. Они применяют автоматическую генерацию контента для финансовых новостей, в которых мало аналитики, но много цифр и фактических данных. Есть три вендора, которые делают такой софт: Narrative Science, Automated Insights и Article Forge. Если зайти на их сайты, то можно увидеть очень много реальных кейсов – примеров публикаций, написанных роботами. Все эти статьи основаны на каких-то фактических данных.

Заметна ли разница между авторским и сгенерированным контентом? В США и в Германии провели исследования, в ходе которых группам журналистов показывали большое количество статей – соответственно, на английском и на немецком языках. Половина текстов была написана людьми, половина – машинами. В среднем люди не могли их различить. А когда испытуемых попросили классифицировать тексты по достоверности и интересности, оказалось, что они находят более достоверными тексты, написанные машиной. При опрошенные отметили, что читать их не так интересно, как «человеческие» статьи.
Выходит, что людям лучше заниматься развлекательным контентом. А если нужно преподнести какую-то новость – используйте машину, ей поверят больше.
Преимущества и опасности
Роботы позволяют вам сфокусироваться на содержании, которое вы хотите вложить в контент, а не на нудном процессе его адаптации под разные форматы. Другое преимущество машин – скорость реакции: если вам нужно быстро обрабатывать инфоповоды, то это ваш инструмент. О пользовательской персонализации мы уже сказали, это несомненный плюс. Четвертое преимущество – краудсорсинг: если вы пользуетесь большим количеством источников, то машина сможет автоматически классифицировать получаемые из них сведения, отличать хорошие от плохих, выбирать адекватные.

Есть и потенциальные опасности. Первая – эхо-камера. Контент, который мне показывают, персонализируется на основе схожести моих интересов – с учетом того, что я уже читал, и интересов похожих на меня людей. Таким образом после некоторого числа итераций я начинаю вариться в своем замкнутом информационном поле.
Вторая опасность – информационные пузыри. Если создать какую-то вымышленную ситуацию, событие, машина может написать под нее много разных вариантов публикаций, выглядящих достоверно. При помощи ботов, социальных сетей и так далее такую дезинформацию можно распространить на огромные аудитории.

Сейчас заговорили о так называемых адверзириал-атаках на нейросети. Приводится пример с логотипом KFC: если показать такую картинку самоуправляемому автомобилю, он тут же встанет – искусственный интеллект распознает изображение как знак «стоп». Если подобные манипуляции возможны с текстами, то соответствующий некоему алгоритму бессмысленный набор слов сможет получить высокий рейтинг нейросетей, а читатель увидит какую-то абракадабру.

К счастью, на практике провести такую атаку очень сложно. Вспомним, что нейросеть – как и наш мозг – приводит любое изображение в соответствие с внутренним представлением. Посмотрите на картинку: слева лица, как мы их видим, а справа – как видит нейросеть. Имея доступ к самой нейросети, картинки можно подобрать, как в примере с логотипом KFC. На самом деле проблема известна еще из криптографии, потому что это аналог взлома хеш-функции. Нейросеть в данном случае и есть хеш-функция: вы преобразовываете некий длинный текст в небольшое внутреннее представление. Если подберете что-то, что совпадает – взломаете. Но чтобы иметь возможность перебора, вам нужно получить доступ к алгоритму.
Не конкурент, а помощник
Практически во всех публикациях на эту тему поднимается проблема востребованности журналистов в будущем. Вопрос, как мне кажется, не совсем правильный: кого-то заменят, кого-то — нет, но понятно, что всю журналистику точно нельзя заменить машинами. Человек уступит им только какие-то базовые, банальные, простые публикации. Проблема в другом: поскольку базовые публикации можно создавать автоматически и сделать это легко, то в процентном соотношении очень скоро сгенерированного контента будет гораздо больше, чем написанного людьми. Как мы уже выяснили, сгенерированный контент с точки зрения достоверности воспринимается лучше – и это позволяет создать мощнейший инструмент по манипуляции сознанием, восприятием. Вот это, наверное, страшнее и важнее всего.
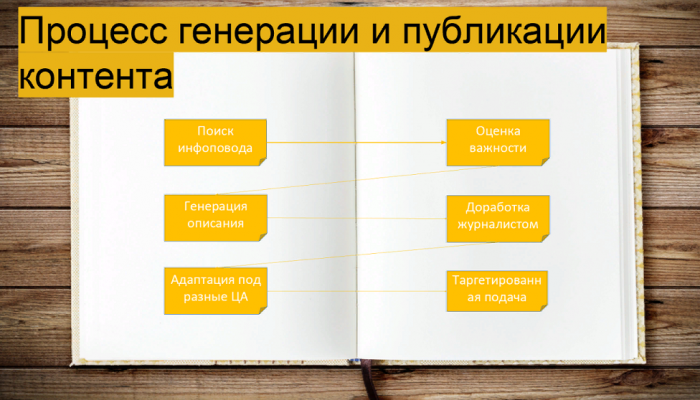
Для создания контента с использованием машинного обучения используется процесс взаимодействия «человек-машина» – не по-отдельности, а вместе, в паре. Сначала машина ищет инфоповоды, классифицирует их, прогнозирует важность, генерирует контент… Это кейс для случая, когда у нас есть большой поток разного рода информации, и мы хотим на нее быстро реагировать. Если у вас есть время подумать и так далее – это совсем другой сценарий. Подготовленный машиной контент попадает к журналисту или редактору, который смотрит, оценивает, дописывает. Дальше текст может идти в публикацию или снова роботу – с тем, чтобы сформировать разные варианты публикации под различные целевые аудитории. После этого машина занимается персонализацией, выбирает для каждого человека, что ему показать. Конечно, не везде это реализовано все вместе, но общий воркфлоу выглядит примерно так.
Человек из процесса подготовки контента не исключается. Роботы – не более чем дополнительные инструменты, которые ускоряют и упрощают процесс, снимают с нас рутинные задачи.
- Источник(и):
- Войдите на сайт для отправки комментариев
