Нейросеть предсказала движения человека по видео
Друзья, с момента основания проекта прошло уже 20 лет и мы рады сообщать вам, что сайт, наконец, переехали на новую платформу.
Какое-то время продолжим трудится на общее благо по адресу
На новой платформе мы уделили особое внимание удобству поиска материалов.
Особенно рекомендуем познакомиться с работой рубрикатора.
Спасибо, ждём вас на N-N-N.ru
Американские разработчики создали алгоритм, который, получая видео с действиями человека, предсказывает его следующие действия в виде анимированной 3D-модели. К примеру, он достаточно точно предсказывает, как будет происходить бросок мяча, увидев только начало замаха руки, рассказывают авторы препринта, опубликованного на arXiv.org. Доклад о разработке будет представлен на конференции ICCV 2019.
Увидев человека, совершающего какое-либо действие, к примеру, идущего по улице, мы можем в общих чертах представить себе, что он будет делать дальше и как это будет выглядеть. Для компьютерных алгоритмов эта задача достаточно нетривиальна. Разработчики начали решать эту проблему давно и в этой области уже есть некоторые наработки, но они имеют ограничения. К примеру, некоторые алгоритмы работают только с одним кадром и не учитывают предыдущие состояния человека, а также не создают полноценную анимированную 3D-модель.
Группа разработчиков из Калифорнийского университета в Беркли под руководством Джитендры Малика (Jitendra Malik) создала алгоритм, способный по последовательности кадров напрямую предсказать будущее поведение человека в виде 3D-модели.
Алгоритм состоит из нескольких частей и этапов, но в нем можно выделить два ключевых этапа. В качестве исходных данных он получает последовательность кадров с двигающимся человеком. Для каждого кадра остаточная сверточная нейросеть ResNet-50 создает вектор, описывающий текущее состояние человека. На основе последовательности этих векторов нейросетевой кодировщик создает единое представление, которое описывает движения человека с начала ролика до текущего кадра.
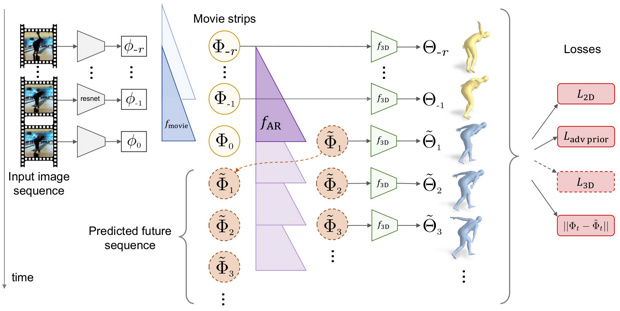 Схема работы алгоритма / Jason Zhang et al. / ICCV 2019
Схема работы алгоритма / Jason Zhang et al. / ICCV 2019
Затем еще одна нейросеть создает на основе множества таких представлений до текущего кадра представление для следующего кадра. Затем этот процесс повторяется, но в качестве исходных данных уже используются не только настоящие представления, но и спрогнозированные. Каждое из этих представлений отдается нейросети, которая выдает 82 параметра, описывающих 3D-модель. Одно из следствий использования 3D-модели заключается в том, что она позволяет увидеть будущие действия человека с любого ракурса.
Разработчики обучили алгоритм на четырех публично доступных датасетах, в том числе Human3.6M, содержащем пары из видео и сопоставленных анимированных 3D-моделей. В основном эти датасеты содержали данные о спортивных действиях, к примеру, бросках мячей. В результате авторам удалось обучить алгоритм достаточно точно предсказывать движения людей, хотя некоторые расхождения с реальными видео все же есть.
- Источник(и):
- Войдите на сайт для отправки комментариев
