Эволюция нейросетей от Т9 до ChatGPT: объясняем на простом русском, как работают языковые модели
Друзья, с момента основания проекта прошло уже 20 лет и мы рады сообщать вам, что сайт, наконец, переехали на новую платформу.
Какое-то время продолжим трудится на общее благо по адресу
На новой платформе мы уделили особое внимание удобству поиска материалов.
Особенно рекомендуем познакомиться с работой рубрикатора.
Спасибо, ждём вас на N-N-N.ru
Автор: Котенков Игорь. В последнее время нам почти каждый день рассказывают в новостях, какие очередные вершины покорили языковые нейросетки, и почему они уже через месяц совершенно точно оставят лично вас без работы. При этом мало кто понимает — а как вообще нейросети вроде ChatGPT работают внутри? Так вот, устраивайтесь поудобнее: в этой статье мы, наконец, объясним всё так, чтобы понял даже шестилетний гуманитарий!
На всякий случай сразу оговоримся: у этой статьи два автора. За всю техническую часть (и за всё хорошее в статье) отвечал Игорь Котенков — широко известный чувак в узких кругах русскоязычной тусовки специалистов по искусственному интеллекту, а также автор канала Сиолошная про машинное обучение, космос и технологии. За мольбы «вот тут непонятно, давай как нибудь попроще!» и за добавление кринжовых неуместных мемов был ответственен Павел Комаровский — автор канала RationalAnswer про рациональный подход к жизни и финансам.
Собственно, статья так и родилась: Павел пришел к Игорю и возмутился — дескать, «почему никто еще не написал на русском нормальную статью про ChatGPT, объясняющую понятно даже для моей бабушки, как всё вот это нейроколдунство работает?». Так что заранее приносим свои извинения всем хардкорным технарям: при подготовке этого текста мы стремились к максимальному упрощению. Нашей задачей было — дать читателям общее понимание принципов работы языковых нейросетей на уровне концепций и аналогий, а не разобрать до последнего винтика все глубокие технические нюансы процесса.
 OpenAI (компанию, сделавшую ChatGPT) основали в 2015 году именно вот эти двое парнишек – кто бы тогда знал, во что это в итоге выльется…
OpenAI (компанию, сделавшую ChatGPT) основали в 2015 году именно вот эти двое парнишек – кто бы тогда знал, во что это в итоге выльется…
В общем, наливайте себе кружечку горячего чая и устраивайтесь поудобнее — сейчас мы вам расскажем всё про то, что там крутится под капотом у языковых моделей, каким образом эти покемоны эволюционировали до текущих (местами поразительных) способностей, и почему взрывная популярность чат бота ChatGPT стала полным сюрпризом даже для его создателей. Поехали!
Навигатор
- T9: сеанс языковой магии с разоблачением
- Откуда нейросети берут вероятности слов?
- Парадокс Барака, или зачем языковым моделям уметь в творчество
- 2018: GPT-1 трансформирует языковые модели
- 2019: GPT-2, или как запихнуть в языковую модель семь тысяч Шекспиров
- Почему в мире языковых моделей больше ценятся именно модели «Plus Size»
- 2020: GPT-3, или как сделать из модели Невероятного Халка
- Промпты, или как правильно уламывать модель
- Январь 2022: InstructGPT, или как научить робота не зиговать
- Ноябрь 2022: ChatGPT, или маленькие секреты большого хайпа
- Подведем итоги
T9: сеанс языковой магии с разоблачением
Начнем с простого. Чтобы разобраться в том, что такое ChatGPT с технической точки зрения, надо сначала понять, чем он точно не является. Это не «Бог из машины», не разумное существо, не аналог школьника (по уровню интеллекта и умению решать задачи), не джинн, и даже не обретший дар речи Тамагочи. Приготовьтесь услышать страшную правду: на самом деле, ChatGPT — это Т9 из вашего телефона, но на бычьих стероидах! Да, это так: ученые называют обе этих технологии «языковыми моделями» (Language Models); а всё, что они по сути делают, — это угадывают, какое следующее слово должно идти за уже имеющимся текстом.
Ну, точнее, в совсем олдовых телефонах из конца 90-х (вроде культовой неубиваемой Nokia 3210) оригинальная технология Т9 лишь ускоряла набор на кнопочных телефонах за счет угадывания текущего вводимого, а не следующего слова. Но технология развивалась, и к эпохе смартфонов начала 2010-х она уже могла учитывать контекст (предыдущее слово), ставить пунктуацию и предлагать на выбор слова, которые могли бы идти следующими. Вот именно об аналогии с такой «продвинутой» версией T9/автозамены и идет речь.
 Кого ни разу не подставляла автозамена на телефоне – пусть первый бросит в меня камень
Кого ни разу не подставляла автозамена на телефоне – пусть первый бросит в меня камень
Итак, и Т9 на клавиатуре смартфона, и ChatGPT обучены решать до безумия простую задачу: предсказание единственного следующего слова. Это и есть языковое моделирование – когда по некоторому уже имеющемуся тексту делается вывод о том, что должно быть написано дальше. Чтобы иметь возможность делать такие предсказания, языковым моделям под капотом приходится оперировать вероятностями возникновения тех или иных слов для продолжения. Ведь, скорее всего, вы были бы недовольны, если бы автозаполнение в телефоне просто подкидывало вам абсолютно случайные слова с одинаковой вероятностью.
Представим для наглядности, что вам прилетает сообщение от приятеля: «Чё, го седня куда нить?». Вы начинаете печатать в ответ: «Да не, у меня уже дела(( я иду в…», и вот тут подключается Т9. Если он предложит вам закончить предложение полностью рандомным словом, типа «я иду в капибару» — то для такой белиберды, если честно, никакая хитрая языковая модель особо и не нужна. Реальные же модели автозаполнения в смартфонах подсказывают гораздо более уместные слова (можете сами проверить прямо сейчас).
 Мой Samsung Galaxy предлагает такие варианты. Сразу видно типичного айтишника: получил зарплату, прокутил – и сразу в аптеку, лечиться!
Мой Samsung Galaxy предлагает такие варианты. Сразу видно типичного айтишника: получил зарплату, прокутил – и сразу в аптеку, лечиться!
Так, а как конкретно Т9 понимает, какие слова будут следовать за уже набранным текстом с большей вероятностью, а какие предлагать точно не стоит? Для ответа на этот вопрос нам придется погрузиться в базовые принципы работы самых простейших нейросеток.
Откуда нейросети берут вероятности слов?
Давайте начнем с еще более простого вопроса: а как вообще предсказывать зависимости одних вещей от других? Предположим, мы хотим научить компьютер предсказывать вес человека в зависимости от его роста — как подойти к этой задаче?
Здравый смысл подсказывает, что надо сначала собрать данные, на которых мы будем искать интересующие нас зависимости (для простоты ограничимся одним полом — возьмем статистику по росту/весу для нескольких тысяч мужчин), а потом попробуем «натренировать» некую математическую модель на поиск закономерности внутри этих данных.
Для наглядности сначала нарисуем весь наш массив данных на графике: по горизонтальной оси X будем откладывать рост в сантиметрах, а по вертикальной оси Y — вес.
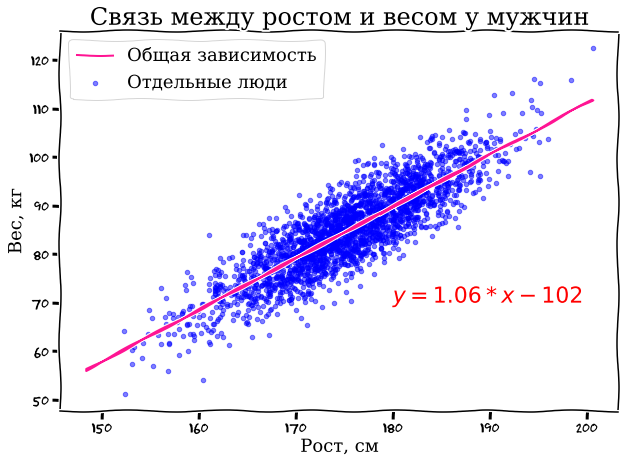 Судя по нашим прикидкам, мужики в выборке попались в среднем ну такие – довольно упитанные (или сплошь качки на массе, тут сразу не разберешь)
Судя по нашим прикидкам, мужики в выборке попались в среднем ну такие – довольно упитанные (или сплошь качки на массе, тут сразу не разберешь)
Даже невооруженным взглядом видна определенная зависимость: высокие мужики, как правило, больше весят (спасибо, кэп!). И эту зависимость довольно просто выразить в виде обычного линейного уравнения y=k*x+b, знакомого нам всем с пятого класса школы. На картинке нужная нам линия уже проведена с помощью модели линейной регрессии — по сути, она позволяет подобрать коэффициенты уравнения k и b таким образом, чтобы получившаяся линия оптимально описывала ключевую зависимость в нашем наборе данных (можете для интереса подставить свой рост в сантиметрах вместо x в уравнение на картинке и проверить, насколько точно наша модель угадает ваш вес).
Вы тут уже наверняка хотите воскликнуть: «Окей, с ростом/весом и так интуитивно всё было понятно, только причем тут вообще языковые нейросети?» А притом, что нейросети — это и есть набор примерно тех же самых уравнений, только куда более сложных и использующих матрицы (но не будем сейчас об этом).
Можно упрощенно сказать, что те же самые T9 или ChatGPT — это всего лишь хитрым образом подобранные уравнения, которые пытаются предсказать следующее слово (игрек) в зависимости от набора подаваемых на вход модели предыдущих слов (иксов). Основная задача при тренировке языковой модели на наборе данных — подобрать такие коэффициенты при этих иксах, чтобы они действительно отражали какую то зависимость (как в нашем примере с ростом/весом). А под большими моделями мы далее будем понимать такие, которые имеют очень большое количество параметров. В области ИИ их прямо так и называют — LLM, Large Language Models. Как мы увидим чуть дальше, «жирная» модель с множеством параметров — это залог успеха для генерации крутых текстов!
Кстати, если вы в этом месте уже недоумеваете, почему мы всё время говорим о «предсказании одного следующего слова», тогда как тот же ChatGPT бодро отвечает целыми портянками текста – то не ломайте зря голову. Языковые модели без всякого труда генерируют длинные тексты, но делают они это по принципу «слово за словом». По сути, после генерации каждого нового слова, модель просто заново прогоняет через себя весь предыдущий текст вместе с только что написанным дополнением – и выплевывает последующее слово уже с учетом него. В результате получается связный текст.
Парадокс Барака, или зачем языковым моделям уметь в творчество
На самом деле, в наших уравнениях в качестве «игрека» языковые модели пытаются предсказать не столько конкретное следующее слово, сколько вероятности разных слов, которыми можно продолжить заданный текст. Зачем это нужно, почему нельзя всегда искать единственное, «самое правильное» слово для продолжения? Давайте разберем на примере небольшой игры.
Правила такие: вы притворяетесь языковой моделью, а я вам предлагаю продолжить текст «44-й президент США (и первый афроамериканец на этой должности) — это Барак…». Подставьте слово, которое должно стоять вместо многоточия, и оцените вероятность, что оно там действительно окажется.
 Ваш ход, маэстро!
Ваш ход, маэстро!
Если вы сейчас сказали, что следующим словом должно идти «Обама» с вероятностью 100%, то поздравляю — вы ошиблись! И дело тут не в том, что существует какой то другой мифический Барак: просто в официальных документах имя президента часто пишется в полной форме, с указанием его второго имени (middle name) — Хуссейн. Так что правильно натренированная языковая модель должна, по хорошему, предсказать, что в нашем предложении «Обама» будет следующим словом только с вероятностью условно в 90%, а оставшиеся 10% выделить на случай продолжения текста «Хуссейном» (после которого последует Обама уже с вероятностью, близкой к 100%).
И тут мы с вами подходим к очень интересному аспекту языковых моделей: оказывается, им не чужда творческая жилка! По сути, при генерации каждого следующего слова, такие модели выбирают его «случайным» образом, как бы кидая кубик. Но не абы как — а так, чтобы вероятности «выпадения» разных слов примерно соответствовали тем вероятностям, которые подсказывают модели зашитые внутрь нее уравнения (выведенные при обучении модели на огромном массиве разных текстов).
Получается, что одна и та же модель даже на абсолютно одинаковые запросы может давать совершенно разные варианты ответа — прямо как живой человек. Вообще, ученые когда то пытались заставить нейронки всегда выбирать в качестве продолжения «наиболее вероятное» следующее слово — что на первый взгляд звучит логично, но на практике такие модели почему то работают хуже; а вот здоровый элемент случайности идет им строго на пользу (повышает вариативность и, в итоге, качество ответов).
 Учитывая вышесказанное, не советую вам спорить с нейросетками, используя способность к творчеству как аргумент за превосходство человеческого разума – может выйти конфуз
Учитывая вышесказанное, не советую вам спорить с нейросетками, используя способность к творчеству как аргумент за превосходство человеческого разума – может выйти конфуз
Вообще, наш язык — это особая структура с (иногда) четкими наборами правил и исключений. Слова в предложениях не появляются из ниоткуда, они связаны друг с другом. Эти связи неплохо выучиваются человеком «в автоматическом режиме» — во время взросления и обучения в школе, через разговоры, чтение, и так далее. При этом для описания одного и того же события или факта люди придумывают множество способов в разных стилях, тонах и полутонах. Подход к языковой коммуникации у гопников в подворотне и, к примеру, у учеников младшей школы будет, скорее всего, совсем разным.
Всю эту вариативность описательности языка и должна в себя вместить хорошая модель. Чем точнее модель оценивает вероятности слов в зависимости от нюансов контекста (предшествующей части текста, описывающей ситуацию) — тем лучше она способна генерировать ответы, которые мы хотим от нее услышать.
 ChatGPT показывает мастер-класс по вариативности: всегда приятно перетереть с понимающим кентом, который ровно объяснит, чё почём – увожение!
ChatGPT показывает мастер-класс по вариативности: всегда приятно перетереть с понимающим кентом, который ровно объяснит, чё почём – увожение!
Краткое резюме: На текущий момент мы выяснили, что несложные языковые модели применяются в функциях «T9/автозаполнения» смартфонов с начала 2010-х; а сами эти модели представляют собой набор уравнений, натренированных на больших объемах данных предсказывать следующее слово в зависимости от поданного «на вход» исходного текста.
2018: GPT-1 трансформирует языковые модели
Давайте уже переходить от всяких дремучих T9 к более современным моделям: наделавший столько шума ChatGPT является наиболее свежим представителем семейства моделей GPT. Но чтобы понять, как ему удалось обрести столь необычные способности радовать людей своими ответами, нам придется сначала вернуться к истокам.
- Источник(и):
- Войдите на сайт для отправки комментариев
