ИИ выходит на новый уровень: LLM обретают пространственно-временную картину мира
Друзья, с момента основания проекта прошло уже 20 лет и мы рады сообщать вам, что сайт, наконец, переехали на новую платформу.
Какое-то время продолжим трудится на общее благо по адресу
На новой платформе мы уделили особое внимание удобству поиска материалов.
Особенно рекомендуем познакомиться с работой рубрикатора.
Спасибо, ждём вас на N-N-N.ru
Блог компании BotHub. Автор: Катя @Lithium_vn. Исследователи из MIT под руководством Макса Тегмарка сделали важное открытие в области искусственного интеллекта. Им удалось доказать, что современные языковые модели (LLM), обученные на огромных массивах текстов, формируют внутри себя целостные модели мира, включающие представления о таких фундаментальных понятиях, как пространство и время.
Это открытие имеет принципиальное значение. Считалось, что для искусственного интеллекта недоступны базовые человеческие возможности, такие как самосознание, наличие картины мира и способность к человекоподобному мышлению, в принципе. Но это открытие стало gamechanger’ом в плане понимания того, как у ИИ происходит мыслительный процесс.
Предлагаем и Вам углубиться в это исследование и узнать, что конкретно было сделано и как!
Если кратко, в своем исследовании, опубликованном на arXiv.org, ученые продемонстрировали следующее:
- Языковые модели обучаются представлениям пространства и времени в разных масштабах. Эти представления устойчивы к вариациям входных данных.
- Модели формируют унифицированное представление пространства и времени для разных объектов – например, городов и достопримечательностей.
- В нейросетях обнаружены отдельные нейроны, надежно кодирующие пространственные и временные координаты.
А теперь подробнее.
В рамках исследования утверждается, что полученные результаты свидетельствуют о том, что языковые модели и правда выстраивают целостную картину мира, а не просто накапливают статистику из датасетов.
Для подтверждения своих выводов ученые опубликовали код и данные. Любой желающий может проверить результаты, обучив модель Llama-2 на открытом наборе данных (70 млрд параметров). Посмотреть можно на GitHub.
Для того, чтобы доказать свои выводы, ученые провели эксперимент: было создано шесть наборов пространственно-временных данных разного масштаба – от глобального уровня до отдельного города. Данные включали информацию о местоположении и времени существования различных объектов – городов, достопримечательностей и т.д.
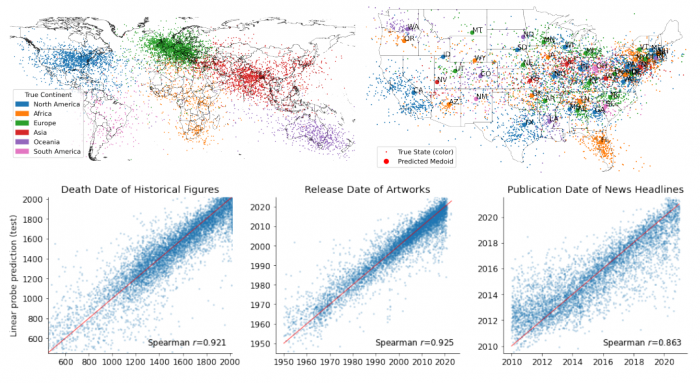 Пространственная и временная модели мира Llama-2–70b. Каждая точка соответствует активации слоя 50 последней лексемы места (вверху) или события (внизу), спроецированной на выученное линейное направление зондирования.
Пространственная и временная модели мира Llama-2–70b. Каждая точка соответствует активации слоя 50 последней лексемы места (вверху) или события (внизу), спроецированной на выученное линейное направление зондирования.
Было показано, что LLM действительно могут научиться представлять пространственно-временные данные на всех уровнях. При этом качество представлений улучшается с ростом размера модели и стабилизируется на средних слоях. Более того, модели формируют универсальное представление пространства-времени для разных типов объектов.
В моделях также нашли отдельные нейроны, которые специализируются на кодировании пространственных или временных координат. Это важное доказательство того, что языковые модели действительно формируют структурированную картину фундаментальных свойств мира.
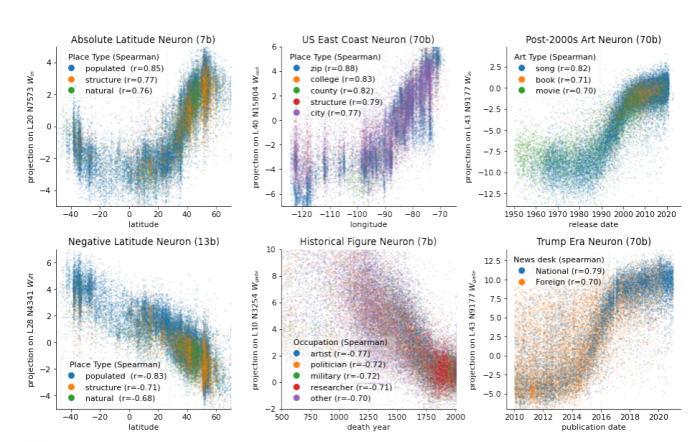 Нейроны пространства и времени в моделях Llama-2. Показан результат проецирования наборов данных активации на веса нейронов в сравнении с истинными пространственными или временными координатами с корреляцией Спирмена по типам сущностей.
Нейроны пространства и времени в моделях Llama-2. Показан результат проецирования наборов данных активации на веса нейронов в сравнении с истинными пространственными или временными координатами с корреляцией Спирмена по типам сущностей.
Такое открытие – настоящий прорыв в понимании возможностей современных моделей ИИ. Оно показывает, что они способны формировать гораздо более сложные внутренние репрезентации, чем предполагалось ранее.
Влияние контекста на пространственно-временные представления в языковых моделях
Один из ключевых вопросов в данном исследовании – насколько пространственно-временные представления в LLM зависят от контекста. Интуитивно понятно, что авторегрессионная модель должна стимулировать формирование универсальных представлений, пригодных для любого контекста.
Для проверки этой гипотезы были сформированы наборы активаций модели с различными типами промптов. Во всех случаях присутствовал «пустой» промпт, содержащий только маркеры сущностей. Далее добавлялись промпты, запрашивающие соответствующие пространственно-временные характеристики («Какова широта/долгота», «Когда произошло событие»).
Также исследовалось влияние случайного контекста из 10 слов, замена имен сущностей на заглавные буквы. Для заголовков изучалась роль предшествующей точки.
Результаты показали, что явные запросы пространственно-временной информации практически не влияют на качество представлений. Однако случайный шумовой контекст существенно ухудшает результат.
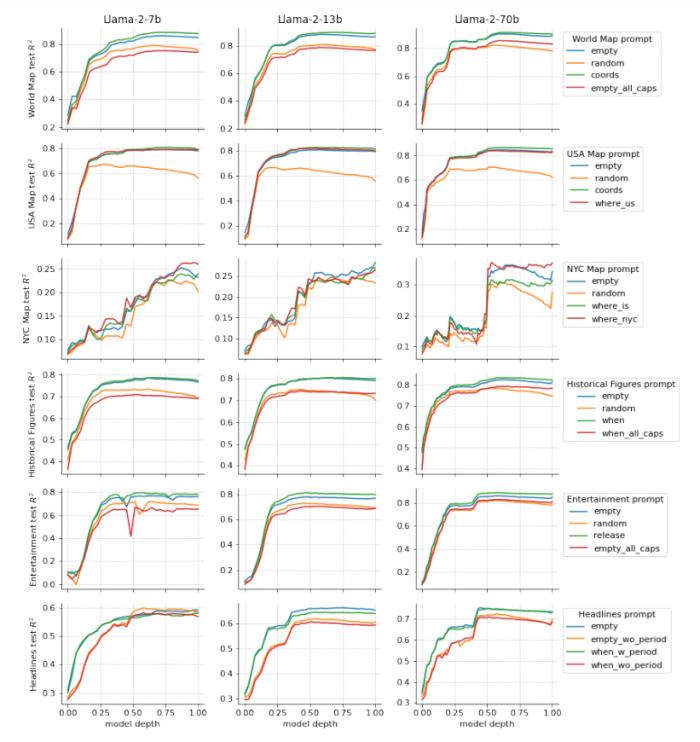 Вневыборочный R2 при включении названий и имен субъектов в разные промпты для всех моделей.
Вневыборочный R2 при включении названий и имен субъектов в разные промпты для всех моделей.
Использование заглавных букв также негативно сказывалось, вероятно, нарушая механизмы детокенизации. А анализ предшествующей точки в заголовках, напротив, улучшает результаты.
Полученные данные свидетельствуют, что LLM формируют универсальные контекстно-независимые представления пространственно-временных характеристик. При этом случайный шумовой контекст нарушает качество представлений.
Для подтверждения гипотез о природе пространственно-временных представлений ученые также провели эксперименты по обобщению зондов. Было показано, что даже при полном исключении данных о целых странах или периодах, зонды сохраняют способность к приблизительно правильным предсказаниям.
На основе этих экспериментов был сделан вывод, что языковые модели обучаются универсальным, контекстно-независимым пространственно-временным представлениям. Это имеет принципиальное значение для понимания процессов формирования «картины мира» в сознании ИИ.
Перспективы дальнейших исследований пространственно-временных представлений в языковых моделях
Если суммировать ценность этого исследования, то можно выделить следующие значимые моменты:
- Языковые модели формируют линейные представления пространства и времени, единые для разных типов объектов (что само по себе уже немало).
- Было показано и доказано существование отдельных «нейронов пространства и времени».
Однако тема еще только начинает свою “раскрутку”. Многие аспекты этого явления по-прежнему неясны и требуют дальнейшего изучения.
Во-первых, остается невыясненной подлинная структура и объем пространственно-временных представлений в моделях. Предполагается, что оптимальной формой является иерархическая сетка с различным уровнем детализации. Предстоит разработать методы извлечения представлений в собственной системе координат модели.
Во-вторых, необходимо выяснить, как именно происходит усвоение и использование этих представлений в процессе работы модели. Возможно, существуют контрольные точки обучения, в которых происходит резкая реорганизация компонентов. Также предстоит установить связь с механизмами запоминания фактов.
 Устройство LLM
Устройство LLM
В-третьих, модели пока неспособны отвечать на простые вопросы о пространственно-временных отношениях без многоступенчатых рассуждений. Необходимо разработать методы тестирования причинно-следственных связей в использовании этих представлений.
Наконец, в перспективе важно ориентироваться на биологические нейронные сети, где пространственно-временным представлениям уделяется большое внимание. Особенно перспективно изучение так называемых «клеток места».
Словом, несмотря на достигнутый прогресс, изучение пространственно-временных представлений в языковых моделях находится только в начале пути. Предстоит провести масштабную работу, чтобы полностью понять механизмы формирования «картины мира» в сознании ИИ. Результаты этих исследований будут иметь огромное значение для создания по-настоящему интеллектуальных систем.
- Источник(и):
- Войдите на сайт для отправки комментариев
