Ученые визуализировали «форму» многомерных данных
Друзья, с момента основания проекта прошло уже 20 лет и мы рады сообщать вам, что сайт, наконец, переехали на новую платформу.
Какое-то время продолжим трудится на общее благо по адресу
На новой платформе мы уделили особое внимание удобству поиска материалов.
Особенно рекомендуем познакомиться с работой рубрикатора.
Спасибо, ждём вас на N-N-N.ru
Исследователи из Сколтеха и Института искусственного интеллекта AIRI представили метод визуализации, который в отличие от существующих аналогов делает сложные биомедицинские, финансовые и иные данные доступными человеку с сохранением многомерной структуры датасета. Потеря этой так называемой топологии датасета не позволяет делать полезные выводы из данных, будь то раковые гены, поведение потребителей или что-то еще.
Исследование опубликовано в числе проектов, представленных на мероприятии уровня A* — Международной конференции по обучению представлений ICLR 2023.
Аналитики компаний и ученые часто имеют дело с базами данных, в которых каждый элемент наделен признаками сразу во многих измерениях. Скажем, банк может использовать широкий круг показателей для описания поведения каждого клиента. Биологи могут сравнивать клетки разных типов с точки зрения того, насколько в них активен каждый из длинного списка генов. Данные по погоде тоже отличаются большим количеством измерений, потому что значения многих параметров фиксируются или предсказываются для множества моментов времени и точек пространства.
При этом людям непривычно мыслить в многомерном пространстве, и если не снизить размерность датасета и не получить его удобное двух- или трехмерное представление, то может быть крайне трудно обнаружить в данных важные закономерности или выдвинуть на основе них продуктивную гипотезу.
«Если данные визуализировать, то они станут интуитивно доступными, осязаемыми, но мы не обязательно увидим их реальную „форму“ — ведь у датасета может быть структура большого масштаба, с кластерами, пустотами, петлями, и хотелось бы, чтобы все это нашло отражение и в представлении пониженной размерности. Тогда физик увидит на визуализации сигналы отдельных частиц, маркетолог — разные группы потребителей, а климатолог — начало и конец интересующего его процесса. Наш метод снижения размерности отличается от аналогов как раз тем, что не жертвует глобальной структурой данных», — поясняет один из авторов исследования, выпускник Сколтеха и сотрудник AIRI Даниил Чернявский.
Существуют разные подходы к снижению размерности данных. Некоторые из них используют автоэнкодеры — нейросети, создающие представления данных в меньшем количестве измерений.
«Проблема в том, что большинство методов, в том числе с автоэнкодерами, работают, что называется, локально. То есть учитывают положение каждой точки относительно ближайших соседей, но в целом игнорируют крупномасштабную структуру датасета, — добавляет Чернявский. — Мы же снабдили автоэнкодер дополнительной новой функцией лосса, которая служит тому, чтобы свести к минимуму различие в топологии между исходным датасетом и его представлением сниженной размерности. Когда лосс равен нулю, „форма“ визуализации гарантированно совпадает с исходной».
Ученые с использованием нескольких метрик оценили, насколько хорошо предложенный метод воспроизводит топологию датасета по сравнению с другими популярными методами снижения размерности данных. Для проверки использовались датасеты разного наполнения и метрики, которые отражают сохранение взаимного расположения точек в целом, а не только тех, что находятся в непосредственной близости друг от друга. Метод авторов исследования повторил исходную «форму» данных лучше всего (см. иллюстрацию).
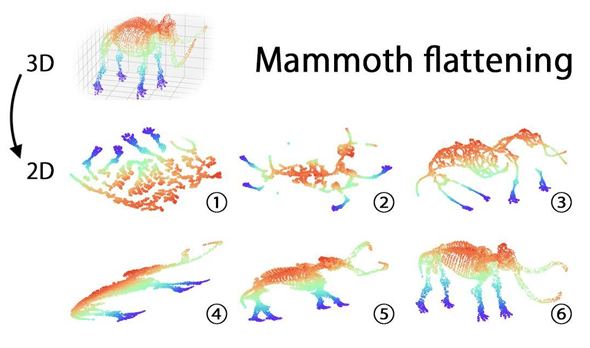 «Расплющивание мамонта». Шесть методов снижения размерности данных превращают трехмерный скан скелета мамонта в плоское представление (в двух измерениях). Видно, что использованный коллективом из Сколтеха и AIRI метод (6), RTD-AE, справляется с сохранением исходной «формы» данных лучше, чем другие популярные методы, а именно: (1) t-SNE, (2) UMAP, (3) PaCMAP, (4) Autoencoder и (5) TopoAE / ©Илья Трофимов / Сколтех
«Расплющивание мамонта». Шесть методов снижения размерности данных превращают трехмерный скан скелета мамонта в плоское представление (в двух измерениях). Видно, что использованный коллективом из Сколтеха и AIRI метод (6), RTD-AE, справляется с сохранением исходной «формы» данных лучше, чем другие популярные методы, а именно: (1) t-SNE, (2) UMAP, (3) PaCMAP, (4) Autoencoder и (5) TopoAE / ©Илья Трофимов / Сколтех
«Топологический анализ обретает все большую популярность как инструмент исследования многомерных данных. Мы рассчитываем, что скоро предложенный нами и другие подобные методы станут признанным стандартом», — считает соавтор исследования профессор Евгений Бурнаев из Центра прикладного искусственного интеллекта Сколтеха и AIRI.
- Источник(и):
- Войдите на сайт для отправки комментариев
