Революционный подход к нейросетям: рассказываем про KAN (Kolmogorov-Arnold Networks)
Автор: The Founder Академия нейросетей. Эволюция архитектуры нейронных сетей уходит корнями в фундаментальные работы, заложенные в 1940-х годах Уорреном Маккаллохом и Уолтером Питcом, которые предложили концепцию искусственных нейронов и их взаимосвязь. Однако значительные прорывы произошли только в 1980-х годах с разработкой алгоритмов обратного распространения ошибки: алгоритм Геоффри Хинтона и других – все это позволило создавать более глубокие нейронные сети и улучшить методы обучения.
В это время появились классические архитектуры, многослойные перцептроны (MLP, и сверточные нейронные сети (CNN), которые революционизировали различные области, включая компьютерное зрение, обработку естественного языка и распознавание образов – теперь мы говорим про своего рода инновационную архитектуру.
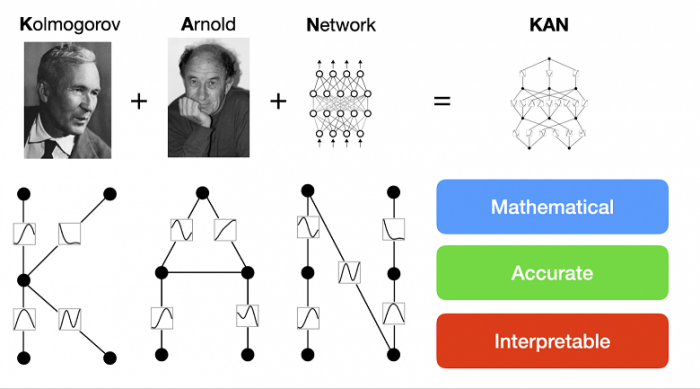
В основе этой новаторской концепции лежит теорема представления Колмогорова-Арнольда, математическая теория, разработанная Владимиром Арнольдом и Андреем Колмогоровым. Причем достаточно давно, вот только исследователи разработали архитектуру и небольшую библиотеку под работу недавно.
Теорема утверждает, что сложные многомерные функции могут быть разложены на более простые одномерные функции, полагая основу для уникальной структуры нейросети KAN.
Проклятие размерности MLP
Входной слой состоит из нейронов, каждый из которых представляет один признак входных данных. Если у вас есть d признаков, то входной слой будет состоять из d нейронов. Эти нейроны просто передают входные значения в первый скрытый слой.
Каждый признак соответствует одному измерению входного вектора. Входной вектор передается в MLP, где каждый элемент вектора (признак) умножается на соответствующий вес и передается на следующий слой.
Проклятие размерности (curse of dimensionality) — это термин, введенный Ричардом Беллманом в 1957 году, описывающий различные феномены, которые возникают при анализе и организации данных в пространствах высокой размерности.
Проклятие размерности в нейронных сетях — это проблема, возникающая при работе с данными, у которых очень много признаков или параметров.
Представьте, что у вас есть таблица с данными, и каждая строка — это набор характеристик какого-то объекта. Чем больше таких характеристик, тем больше измерений у вашего пространства данных.
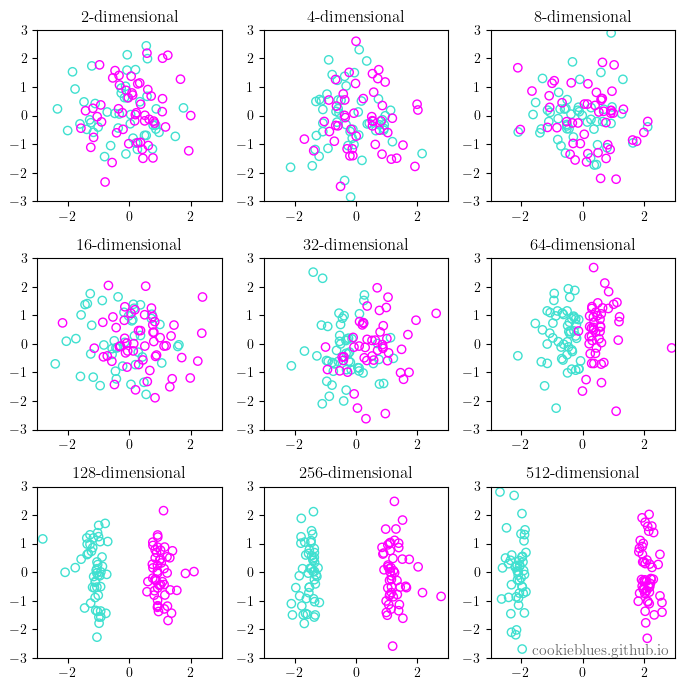
В низкоразмерных пространствах (например, с двумя или тремя признаками) данные располагаются близко к друг другу, поэтому их легко проанализировать. С увеличением числа измерений (размерностей) объём пространства данных растет экспоненциально. Очень быстро.
Представьте, что у нас есть MLP, который должен классифицировать объекты по двум признакам (например, рост и вес).
Это можно представить как двухмерное пространство, где каждый объект описывается точкой с координатами (рост, вес). Допустим, что мы хотим разделить это пространство на области, которые соответствуют различным классам объектов.
Теперь предположим, что у нас появляется третий признак, например возраст. Теперь каждый объект описывается точкой в трёхмерном пространстве (рост, вес, возраст). Модель должна разделить это трёхмерное пространство на области, соответствующие классам объектов.
Для того чтобы обучить MLP эффективно классифицировать объекты в этом высокоразмерном пространстве, нам нужно достаточное количество данных, чтобы покрыть это пространство.
В двухмерном случае для точного представления данных может потребоваться несколько десятков или сотен точек. В d-пространстве, чтобы иметь такую же плотность данных, требуется экспоненциально больше точек — примерно Nd, где N — количество точек данных на одно измерение.
Рассмотрим пример с простым MLP, у которого 100 входных признаков и 50 нейронов в скрытом слое.
Пусть у нас есть 1000 тренировочных примеров. В этом случае соотношение данных к параметрам составляет 1000/5000 = 0.2, что очень мало для эффективного обучения.
Теперь увеличим количество входных признаков до 1000. Количество весов станет 1000×50=50000
Для того чтобы сохранить соотношение данных к параметрам на приемлемом уровне, скажем 10:1, нам потребуется 500000 тренировочных примеров, что существенно больше и может быть трудно достижимо на практике.
Большинство точек данных находятся далеко друг от друга, и статистические закономерности, наблюдаемые в низкоразмерных пространствах, становятся менее значимыми.
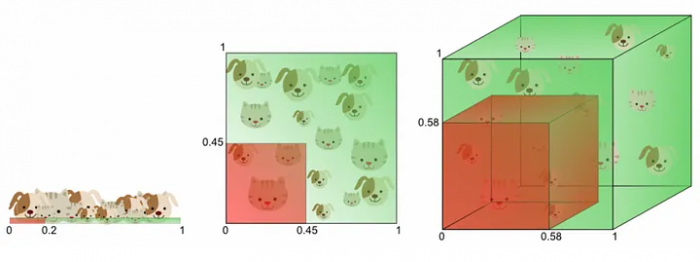 Представьте, что вы стараетесь найти иголку в стоге сена, но теперь сена в тысячу раз больше, чем раньше. Причем вы уже не различаете самые маленькие соломинки из-за их разреженности.
Представьте, что вы стараетесь найти иголку в стоге сена, но теперь сена в тысячу раз больше, чем раньше. Причем вы уже не различаете самые маленькие соломинки из-за их разреженности.
И это мы не говорим про переобучение. В высокоразмерных пространствах нейронные сети требуют большего количества параметров для эффективного обучения, что может привести к переобучению (overfitting). Хотя здесь подключаются “методы регуляризации”.
Это приводит к нескольким сложностям.
Во-первых, для того чтобы модель могла эффективно учиться на таких данных, ей нужно гораздо больше примеров, чтобы покрыть всё это огромное пространство.
Во-вторых, различия между данными становятся менее заметными, и модель может с трудом находить закономерности.
В-третьих, вычислительные ресурсы, необходимые для обработки и анализа этих данных, сильно увеличиваются – в разы.
Для преодоления этих проблем используются различные методы, такие как понижение размерности (например, метод главных компонент (PCA), t-SNE), архитектуры, которые лучше работают с высокоразмерными данными и т.д. Но совсем недавно исследователи предложили новый способ работы. Радикально, но верно.
- Источник(и):
- Войдите на сайт для отправки комментариев
